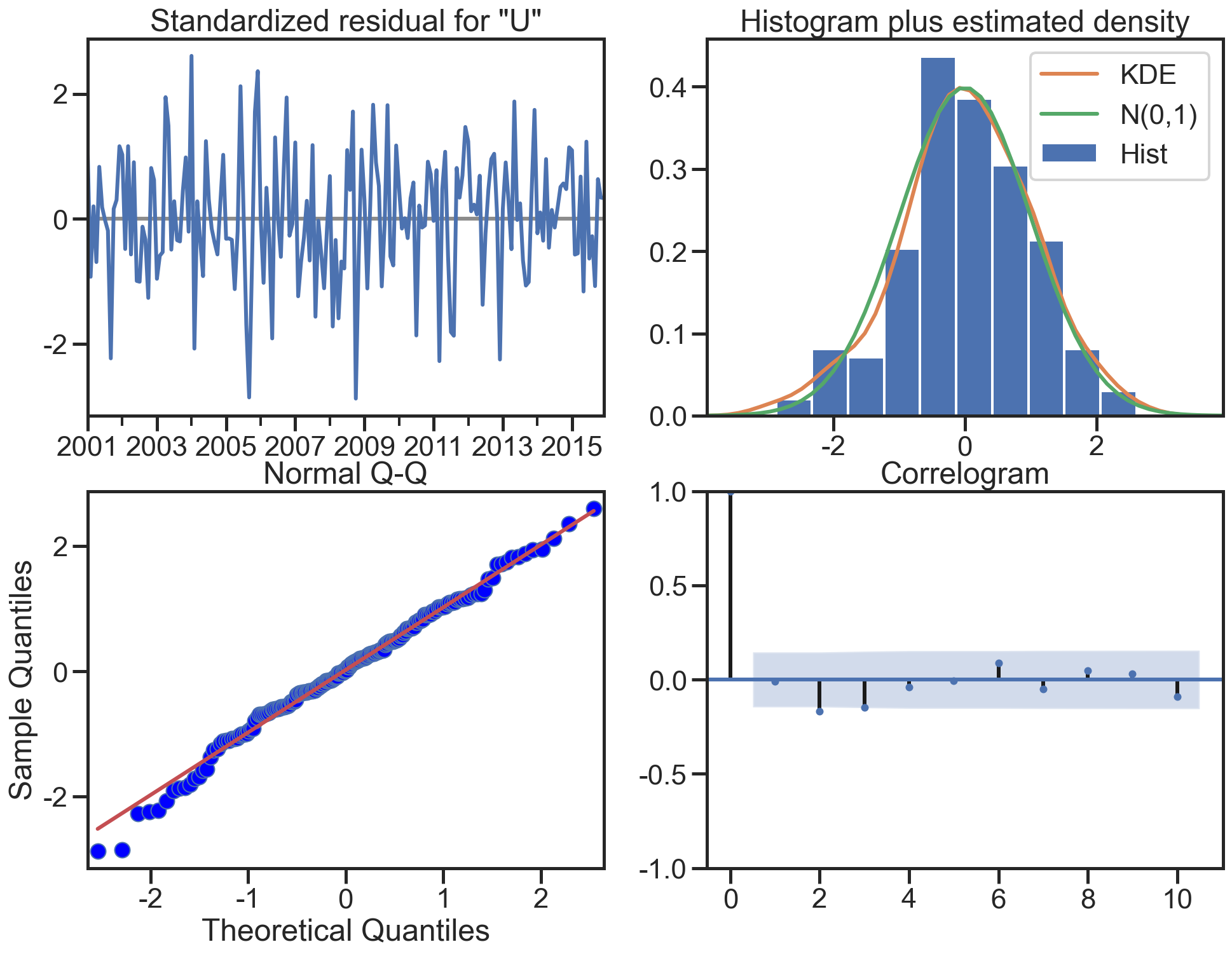
规划问题
线性规划问题
标准形式

样例1

过程
c为所求的z,[2,3,-5]
Ax≤b即,A为[[-2,5,-1][1,3,1]],b为[-10,12]
Aeq为等式左边的[1,1,1],beq为等式右边的[7]
求解参数第一个为-c(因求解c的最大值即求c的最小值),后面依次为A,b,Aeq,beq
注意:Aeq和A的维度,即[]的层数
代码
# 使用scipy实现
from scipy import optimize
import numpy as np
c = np.array([2,3,-5])
A = np.array([[-2,5,-1],[1,3,1]])
B = np.array([-10,12])
Aeq = np.array([[1,1,1]])
Beq = np.array([7])
res = optimize.linprog(-c,A,B,Aeq,Beq)
print(res) con: array([1.80713222e-09])
fun: -14.57142856564506
message: 'Optimization terminated successfully.'
nit: 5
slack: array([-2.24583019e-10, 3.85714286e+00])
status: 0
success: True
x: array([6.42857143e+00, 5.71428571e-01, 2.35900788e-10])
样例2
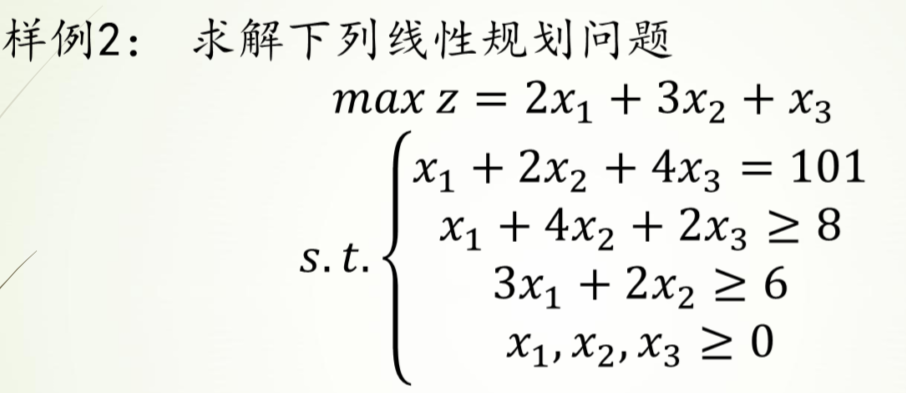
过程
Scipy
c为所求的z,[2,3,1]
Ax≤b即,A为[[-1,-4,-2][-3-2,0]],b为[-8,-6],
Aeq为等式左边的[1,2,4],beq为等式右边的[101]
求解参数第一个为-c(因求解c的最大值即求c的最小值),后面依次为A,b,Aeq,beq
LB,UB不用设置
Pulp
定义问题maximum或者minimum
添加决策变量,离散型或者连续型
设置目标函数
添加约束
求解输出
代码
# pulp库求解
import pulp
# 定义问题
MyProbLP = pulp.LpProblem("LPProbDemo1", sense=pulp.LpMaximize)
# 决策变量
# Continuous连续 Integer离散 lowBound和upBound默认为无穷
x1 = pulp.LpVariable('x1', lowBound=0, cat='Continuous')
x2 = pulp.LpVariable('x2', lowBound=0, cat='Continuous')
x3 = pulp.LpVariable('x3', lowBound=0, cat='Continuous')
MyProbLP += 2 * x1 + 3 * x2 + x3 # 设置目标函数
MyProbLP += (x1 + 4 * x2 + 2 * x3 >= 8) # 不等式约束
MyProbLP += (3 * x1 + 2 * x2 >= 6) # 不等式约束
MyProbLP += (x1 + 2 * x2 + 4 * x3 == 101) # 等式约束
# 求解
MyProbLP.solve()
# 输出结果
print("Status:", pulp.LpStatus[MyProbLP.status]) # 输出求解状态
for v in MyProbLP.variables():
print(v.name, "=", v.varValue) # 输出每个变量的最优值
print("F(x) = ", pulp.value(MyProbLP.objective)) # 输出最优解的目标函数值Status: Optimal
x1 = 101.0
x2 = 0.0
x3 = 0.0
F(x) = 202.0
# 使用scipy实现
from scipy import optimize
import numpy as np
c = np.array([2, 3, 1])
A = np.array([[-1, -4, -2], [-3, -2, 0]])
b = np.array([-8, -6])
Aeq = np.array([[1, 2, 4]])
beq = np.array([101])
# solve
res = optimize.linprog(-c, A, b, Aeq, beq)
print(res) con: array([3.75850107e-09])
fun: -201.9999999893402
message: 'Optimization terminated successfully.'
nit: 6
slack: array([ 93. , 296.99999998])
status: 0
success: True
x: array([1.01000000e+02, 6.13324051e-10, 3.61350245e-10])
运输问题
标准形式

样例1
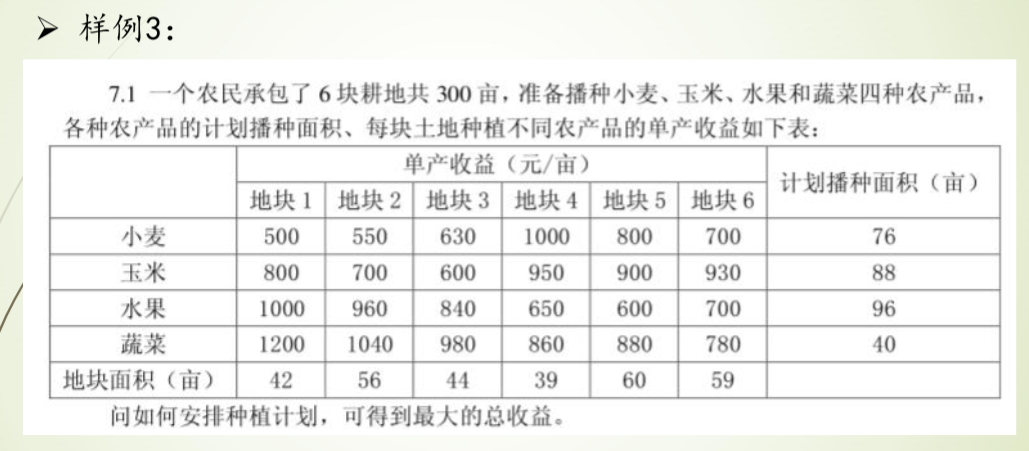
过程
使用pulp
定义问题,获取数据,定义目标函数,添加约束,求解输出
把二维array通过flatten折叠成一维之后方便操作
代码
# 运输问题求解
import pulp
import numpy as np
fruits_name = np.array(['小麦', '玉米', '水果', '蔬菜']) # 水果类型
place_name = np.array(['地块1', '地块2', '地块3', '地块4', '地块5', '地块6']) # 地块
costs = np.array([[500, 530, 630, 1000, 800, 700],
[800, 700, 600, 950, 900, 930],
[1000, 960, 840, 650, 600, 700],
[1200, 1040, 980, 860, 880, 780]]) # 收益
max_plants = np.array([76, 88, 96, 40]) # 每种水果的最大种植量
max_size = np.array([42, 56, 44, 39, 60, 59]) # 地块最大面积
# 定义问题
Problem = pulp.LpProblem("种植最大收益问题", sense=pulp.LpMaximize) # 求最大值
# 数据表的行列数
row = len(costs) # 行
col = len(costs[0]) # 列
# 定义决策变量 从x{i}{j}中遍历加入 最小值为0 离散型变量
var = np.array([[pulp.LpVariable(f'x{i}{j}', lowBound=0, cat=pulp.LpInteger) for j in range(col)] for i in range(row)])
# 转为一维 设置目标函数
Problem += pulp.lpDot(var.flatten(), costs.flatten())
# 加入约束
for i in range(row):
Problem += (pulp.lpSum(var[i]) <= max_plants[i])
for j in range(col):
Problem += (pulp.lpSum((var[i][j] for i in range(row))) <= max_size[j])
# 求解
Problem.solve()
# 打印结果
print(Problem) # 输出问题设定参数和条件
print("优化状态:", pulp.LpStatus[Problem.status])
for v in Problem.variables():
print(v.name, "=", v.varValue)
print("最优收益 = ", pulp.value(Problem.objective))种植最大收益问题:
MAXIMIZE
500*x00 + 530*x01 + 630*x02 + 1000*x03 + 800*x04 + 700*x05 + 800*x10 + 700*x11 + 600*x12 + 950*x13 + 900*x14 + 930*x15 + 1000*x20 + 960*x21 + 840*x22 + 650*x23 + 600*x24 + 700*x25 + 1200*x30 + 1040*x31 + 980*x32 + 860*x33 + 880*x34 + 780*x35 + 0
SUBJECT TO
_C1: x00 + x01 + x02 + x03 + x04 + x05 <= 76
_C2: x10 + x11 + x12 + x13 + x14 + x15 <= 88
_C3: x20 + x21 + x22 + x23 + x24 + x25 <= 96
_C4: x30 + x31 + x32 + x33 + x34 + x35 <= 40
_C5: x00 + x10 + x20 + x30 <= 42
_C6: x01 + x11 + x21 + x31 <= 56
_C7: x02 + x12 + x22 + x32 <= 44
_C8: x03 + x13 + x23 + x33 <= 39
_C9: x04 + x14 + x24 + x34 <= 60
_C10: x05 + x15 + x25 + x35 <= 59
VARIABLES
0 <= x00 Integer
0 <= x01 Integer
0 <= x02 Integer
0 <= x03 Integer
0 <= x04 Integer
0 <= x05 Integer
0 <= x10 Integer
0 <= x11 Integer
0 <= x12 Integer
0 <= x13 Integer
0 <= x14 Integer
0 <= x15 Integer
0 <= x20 Integer
0 <= x21 Integer
0 <= x22 Integer
0 <= x23 Integer
0 <= x24 Integer
0 <= x25 Integer
0 <= x30 Integer
0 <= x31 Integer
0 <= x32 Integer
0 <= x33 Integer
0 <= x34 Integer
0 <= x35 Integer
优化状态: Optimal
x00 = 0.0
x01 = 0.0
x02 = 6.0
x03 = 39.0
x04 = 31.0
x05 = 0.0
x10 = 0.0
x11 = 0.0
x12 = 0.0
x13 = 0.0
x14 = 29.0
x15 = 59.0
x20 = 2.0
x21 = 56.0
x22 = 38.0
x23 = 0.0
x24 = 0.0
x25 = 0.0
x30 = 40.0
x31 = 0.0
x32 = 0.0
x33 = 0.0
x34 = 0.0
x35 = 0.0
最优收益 = 284230.0
整数规划(有待完善)

非线性规划
样例1
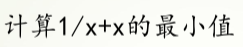
过程
使用scipy.optimize中的minimize求得局部最小值
代码
# 求x+1/x的最小值
from scipy.optimize import minimize
import numpy as np
def fun(args_):
a = args_
return lambda x: a / x[0] + x[0]
if __name__ == "__main__":
args = 1
x0 = np.asarray(2) # 初始猜测值
res = minimize(fun(args), x0, method='SLSQP')
print(res.fun)
print(res.success)
print(res.x)
2.0000000815356342
True
[1.00028559]
样例2
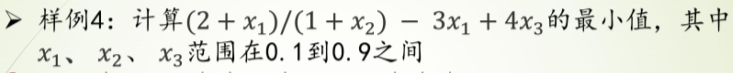
过程
定义表达式
定义约束条件(eq和ineq)
代码
# 定义表达式
import numpy as np
from scipy.optimize import minimize
def fun(_args):
a, b, c, d = _args
return lambda x: (a + x[0]) / (b + x[1]) - c * x[0] + d * x[2]
# 定义约束条件 分为eq和ineq eq表示等于0 ineq表示大于等于0
def con(_args):
x1min, x1max, x2min, x2max, x3min, x3max = _args
_cons = ({'type': 'ineq', 'fun': lambda x: x[0] - x1min},
{'type': 'ineq', 'fun': lambda x: -x[0] + x1max},
{'type': 'ineq', 'fun': lambda x: x[1] - x2min},
{'type': 'ineq', 'fun': lambda x: -x[1] + x2max},
{'type': 'ineq', 'fun': lambda x: x[2] - x3min},
{'type': 'ineq', 'fun': lambda x: -x[2] + x3max})
return _cons
if __name__ == '__main__':
# 定义常量值
args = (2, 1, 3, 4)
# 设置约束
args1 = (0.1, 0.9, 0.1, 0.9, 0.1, 0.9)
cons = con(args1)
# 设置初始猜测值
x0 = np.asarray((0.5, 0.5, 0.5))
# 解决问题
# noinspection PyTypeChecker
res = minimize(fun(args), x0, method='SLSQP', constraints=cons)
# 输出结果
print(res.fun)
print(res.success)
print(res.x)-0.773684210526435
True
[0.9 0.9 0.1]
微分方程解析解
一个例子
from sympy.abc import *
from sympy import *
import sympy
f= sympy.Function('f') # f标记为变量
diffeq = Eq(f(x).diff(x, 2) - 2*f(x).diff(t) + f(x), sin(x))diffeq
dsolve(diffeq,f(x))
阻尼谐振子的二阶ODE
包含initial conditions
t,gamma,omega0=symbols('t,gamma,omega_0') # 定义符号
x= sympy.Function('x') # x标记为变量
# 设置ODE
ODE = Eq(x(t).diff(t, 2) + 2*omega0*gamma*x(t).diff(t) + omega0**2*x(t), 0)
# 定义初始条件
con={x(0):1,diff(x(t),t).subs(t,0): 0}
# 解决
dsolve(ODE,ics=con)
微分方程数值解
场线图与数值解
当ODE无法求得解析解时,可以用scipy中的intergrate.odeint求数值解来探索其解的部分性质,并辅以可视化,能直观的展现ODE解的函数表达
以如下一阶非线性ODE为例
from scipy import integrate
from scipy.integrate import odeint
import numpy as np
import matplotlib.pyplot as plt
import sympy
from sympy import *
plt.rcParams['font.sans-serif']=['Microsoft YaHei']x =sympy.symbols('x')
y=sympy.Function('y')
diffeq = Eq(y(x).diff(x),x-y(x)**2)
diffeq
先尝试用dsolve解决
dsolve(diffeq)
现用odeint求其数值解
odeint()函数是scipy库中一个数值求解微分方程的函数 odeint()函数需要至少三个变量,第一个是微分方程函数,第二个是微分方程初值,第三个是微分的自变量
def diff(y, x):
return np.array(x-y**2)
# dy/dx = x-y^2
# 给出自变量x的范围
x =np.linspace(0,10,100)
# 设定初值为0,此时y为一个数组
y = odeint(diff,0,x)
# 画图
plt.plot(x, y[:, 0]) # y数组(矩阵)的第一列,(因为维度相同,plt.plot(x, y)效果相同)
plt.grid()
plt.show() 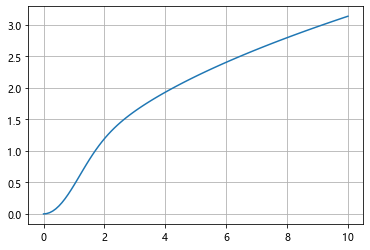
场线图的画法暂时没看懂
# 一个例子
import numpy as np
import matplotlib.pyplot as plt
from scipy.integrate import odeint
def diff(y, x):
return np.array(x)
# 上面定义的函数在odeint里面体现的就是dy/dx = x
x = np.linspace(0, 10, 100) # 给出x范围
y = odeint(diff, 0, x) # 设初值为0 此时y为一个数组,元素为不同x对应的y值
# 也可以直接y = odeint(lambda y, x: x, 0, x)
plt.plot(x, y[:, 0]) # y数组(矩阵)的第一列,(因为维度相同,plt.plot(x, y)效果相同)
plt.title('dy/dx = x')
plt.grid()
plt.show() 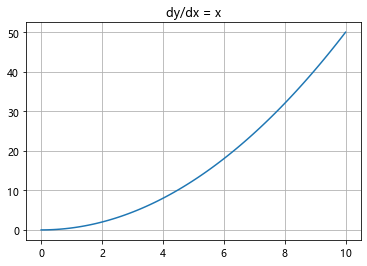
洛伦兹曲线与数值解
代码例
def move(P,steps,sets):
x,y,z = P
sgima,rho,beta = sets
#各方向的速度近似
dx = sgima*(y-x)
dy = x*(rho-z)-y
dz = x*y - beta*z
return [x+dx*steps,y+dy*steps,z+dz*steps]
# 设置sets参数
sets = [10.,28.,3.]
t = np.arange(0,30,0.01)
# 位置1:
P0 = [0.,1.,0.]
P = P0
d = []
for v in t:
P = move(P,0.01,sets)
d.append(P)
dnp = np.array(d)
# 位置2:
P02 = [0.,1.01,0.]
P = P02
d = []
for v in t:
P = move(P,0.01,sets)
d.append(P)
dnp2 = np.array(d)
# 画图
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig = plt.figure()
ax = Axes3D(fig)
ax.plot(dnp[:,0],dnp[:,1],dnp[:,2])
ax.plot(dnp2[:,0],dnp2[:,1],dnp2[:,2])
plt.title('洛伦兹曲线')
plt.show()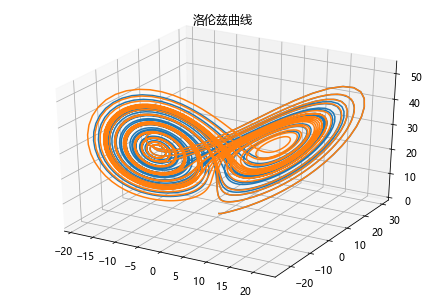
使用odeint解决
# 定义函数
def dmove(w,t,p,r,b):
# 给出 位置矢量w 和三个参数p,r,b计算出
# dx/dt,dy/dt,dp/dt
x,y,z = w
return np.array([p*(y-x),x*(r-z),x*y-b*z])
# 创建时间点
t = np.arange(0,30,0.01)
# 初始点
s1 = (0.,1.,0.)
s2 = (0.,1.01,0.)
# 超参集合
args = (10.,28.,3.)
# p1 p2
p1 =odeint(dmove,s1,t,args=args)
p2 =odeint(dmove,s2,t,args=args)
# 画图
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
fig = plt.figure()
ax = Axes3D(fig)
ax.plot(p1[:,0],p1[:,1],p1[:,2],label = 'P1')
ax.plot(p2[:,0],p2[:,1],p2[:,2],label = 'P2')
plt.title('洛伦兹曲线 by odeint')
plt.legend(loc='best')
plt.show()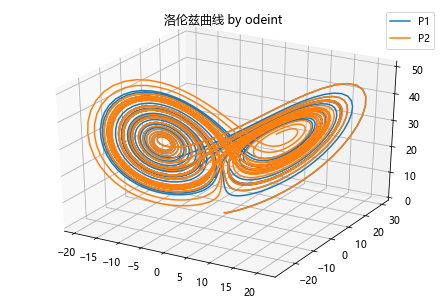
传染病模型
六种传染病模型 SI,SIS,SIR,SIRS,SEIR,SEIRS
艾滋传染模型 SI
普通流感模型 SIS
急性传染病模型 SIR 及其拓展模型 SIRS
带潜伏期的恶性传染病模型 SEIR\
SI-Model
在 SI 模型里面,只考虑了易感者和感染者,并且感染者不能够恢复,此类病症有 HIV 等; 由于艾滋传染之后不可治愈,所以该模型为:易感染者被感染
最简单的SI模型首先把人群分为2种,一种是易感者(Susceptibles),易感者是健康的人群,用S表示其人数,另外一种是感染者(The Infected),人数用 I来表示
假设:
1、在疾病传播期间总人数N不变,N=S+I
2、每个病人每天接触人数为定值\
import scipy.integrate as spi
import numpy as np
import matplotlib.pyplot as plt
# N为人群总数
N = 10000
# β为传染率系数
beta = 0.25
# gamma为恢复率系数
gamma = 0
# I_0为感染者的初始人数
I_0 = 1
# S_0为易感者的初始人数
S_0 = N - I_0
# 感染者每天接触人数
P = 1
# T为传播时间
T = 150
# INI为初始状态下的数组
INI = (S_0,I_0)
def funcSI(inivalue,_):
Y = np.zeros(2)
X = inivalue
# 易感个体变化
Y[0] = - (P * beta * X[0] * X[1]) / N + gamma * X[1]
# 感染个体变化
Y[1] = (P * beta * X[0] * X[1]) / N - gamma * X[1]
return Y
T_range = np.arange(0,T + 1)
RES = spi.odeint(funcSI,INI,T_range)
plt.plot(RES[:,0],color = 'darkblue',label = 'Susceptible',marker = '.')
plt.plot(RES[:,1],color = 'red',label = 'Infection',marker = '.')
plt.title('SI Model')
plt.legend()
plt.xlabel('Day')
plt.ylabel('Number')
plt.show()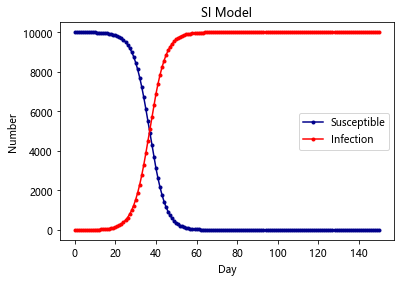
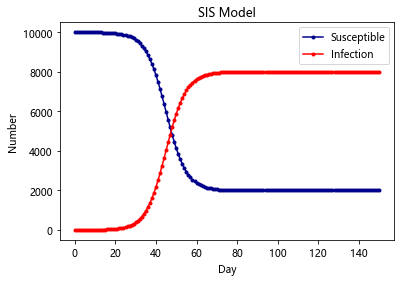
SIS-Model
除了 HIV 这种比较严重的病之外,还有很多小病是可以恢复并且反复感染的,例如日常的感冒,发烧等。在这种情况下,感染者就有一定的几率重新转化成易感者
在SI模型基础上加入康复的概率
import scipy.integrate as spi
import numpy as np
import matplotlib.pyplot as plt
# N为人群总数
N = 10000
# β为传染率系数
beta = 0.25
# gamma为恢复率系数
gamma = 0.05
# I_0为感染者的初始人数
I_0 = 1
# S_0为易感者的初始人数
S_0 = N - I_0
# T为传播时间
T = 150
# INI为初始状态下的数组
INI = (S_0,I_0)
def funcSIS(inivalue,_):
Y = np.zeros(2)
X = inivalue
# 易感个体变化
Y[0] = - (beta * X[0]) / N * X[1] + gamma * X[1]
# 感染个体变化
Y[1] = (beta * X[0] * X[1]) / N - gamma * X[1]
return Y
T_range = np.arange(0,T + 1)
RES = spi.odeint(funcSIS,INI,T_range)
plt.plot(RES[:,0],color = 'darkblue',label = 'Susceptible',marker = '.')
plt.plot(RES[:,1],color = 'red',label = 'Infection',marker = '.')
plt.title('SIS Model')
plt.legend()
plt.xlabel('Day')
plt.ylabel('Number')
plt.show()
SIR-Model
有的时候,感染者在康复之后,就有了抗体,于是后续就不会再获得此类病症,这种时候,考虑SIS模型就不再合适了,需要考虑SIR模型。此类病症有麻疹,腮腺炎,风疹等
SIR是三个单词首字母的缩写,其中S是Susceptible的缩写,表示易感者;I是Infective的缩写,表示感染者;R是Removal的缩写,表示移除者。这个模型本身是在研究这三者的关系。在病毒最开始的时候,所有人都是易感者,也就是所有人都有可能中病毒;当一部分人在接触到病毒以后中病毒了,变成了感染者;感染者会接受各种治疗,最后变成了移除者。
该模型有两个假设条件
1.一段时间内总人数N是不变的,也就是不考虑新生以及自然死亡的人数
2.从S到I的变化速度α、从I到R的变化速度β也是保持不变的
3.移除者不再被感染
import scipy.integrate as spi
import numpy as np
import matplotlib.pyplot as plt
# N为人群总数
N = 10000
# β为传染率系数
beta = 0.25
# gamma为恢复率系数
gamma = 0.05
# I_0为感染者的初始人数
I_0 = 1
# R_0为治愈者的初始人数
R_0 = 0
# S_0为易感者的初始人数
S_0 = N - I_0 - R_0
# T为传播时间
T = 150
# INI为初始状态下的数组
INI = (S_0,I_0,R_0)
def funcSIR(inivalue,_):
Y = np.zeros(3)
X = inivalue
# 易感个体变化
Y[0] = - (beta * X[0] * X[1]) / N
# 感染个体变化
Y[1] = (beta * X[0] * X[1]) / N - gamma * X[1]
# 治愈个体变化
Y[2] = gamma * X[1]
return Y
T_range = np.arange(0,T + 1)
RES = spi.odeint(funcSIR,INI,T_range)
plt.plot(RES[:,0],color = 'darkblue',label = 'Susceptible',marker = '.')
plt.plot(RES[:,1],color = 'red',label = 'Infection',marker = '.')
plt.plot(RES[:,2],color = 'green',label = 'Recovery',marker = '.')
plt.title('SIR Model')
plt.legend()
plt.xlabel('Day')
plt.ylabel('Number')
plt.show()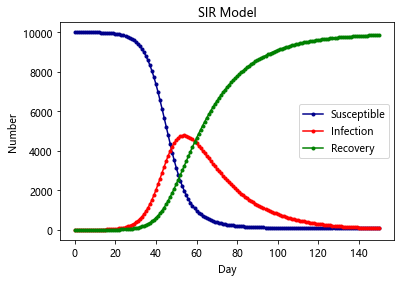
SEIR-Model(更加贴合新冠)
SEIR模型加入了扰动因子v,前面三种模型也可以加入扰动因子,加入扰动因子的模型往往更合理
原因:就拿SEIR模型来说,它不是万能的,总有一些异常状况,如有的人潜伏期短,有的人潜伏期长,还可能有超级感染者,有的潜伏者可能就直接痊愈了,变成了抵抗者。方程并没有单独处理这些情况,因为一定程度内这些异类都可以被扰动因子所包含。研究一个固定的模型加扰动项,比不断地往模型里加扰动项好研究的多
通过对 SEIR 模型的研究, 可以预测一个封闭地区疫情的爆发情况, 最大峰值, 感染人数等等 但是显然没有任何地区是封闭的, 所以就要把各个地区看成图的节点, 地区之间的流动可以由马尔可夫转移所刻画, 对每个结点单独跑 SEIR 模型
最后整个仿真模型就可以比较准确的反应疫情的散播和爆发情况
当然可以再加入更多的决策因素
在其他模型的基础上,加入传染病潜伏期的存在
import scipy.integrate as spi
import numpy as np
import matplotlib.pyplot as plt
# N为人群总数
N = 10000
# β为传染率系数
beta = 0.6
# gamma为恢复率系数
gamma = 0.1
# Te为疾病潜伏期
Te = 14
# I_0为感染者的初始人数
I_0 = 1
# E_0为潜伏者的初始人数
E_0 = 0
# R_0为治愈者的初始人数
R_0 = 0
# S_0为易感者的初始人数
S_0 = N - I_0 - E_0 - R_0
# T为传播时间
T = 150
# INI为初始状态下的数组
INI = (S_0,E_0,I_0,R_0)
def funcSEIR(inivalue,_):
Y = np.zeros(4)
X = inivalue
# 易感个体变化
Y[0] = - (beta * X[0] * X[2]) / N
# 潜伏个体变化(每日有一部分转为感染者)
Y[1] = (beta * X[0] * X[2]) / N - X[1] / Te
# 感染个体变化
Y[2] = X[1] / Te - gamma * X[2]
# 治愈个体变化
Y[3] = gamma * X[2]
return Y
T_range = np.arange(0,T + 1)
RES = spi.odeint(funcSEIR,INI,T_range)
plt.plot(RES[:,0],color = 'darkblue',label = 'Susceptible',marker = '.')
plt.plot(RES[:,1],color = 'orange',label = 'Exposed',marker = '.')
plt.plot(RES[:,2],color = 'red',label = 'Infection',marker = '.')
plt.plot(RES[:,3],color = 'green',label = 'Recovery',marker = '.')
plt.title('SEIR Model')
plt.legend()
plt.xlabel('Day')
plt.ylabel('Number')
plt.show()
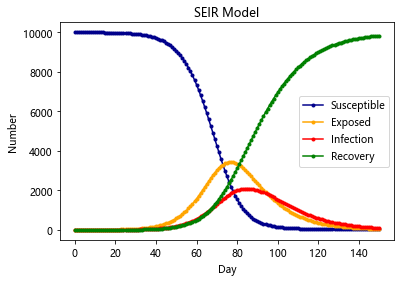
SIRS-Model
与SIR不同在于,康复者的免疫力是暂时的,康复者会转化为易感者
import scipy.integrate as spi
import numpy as np
import matplotlib.pyplot as plt
# N为人群总数
N = 10000
# β为传染率系数
beta = 0.25
# gamma为恢复率系数
gamma = 0.05
# Ts为抗体持续时间
Ts = 7
# I_0为感染者的初始人数
I_0 = 1
# R_0为治愈者的初始人数
R_0 = 0
# S_0为易感者的初始人数
S_0 = N - I_0 - R_0
# T为传播时间
T = 150
# INI为初始状态下的数组
INI = (S_0,I_0,R_0)
def funcSIRS(inivalue,_):
Y = np.zeros(3)
X = inivalue
# 易感个体变化
Y[0] = - (beta * X[0] * X[1]) / N + X[2] / Ts
# 感染个体变化
Y[1] = (beta * X[0] * X[1]) / N - gamma * X[1]
# 治愈个体变化
Y[2] = gamma * X[1] - X[2] / Ts
return Y
T_range = np.arange(0,T + 1)
RES = spi.odeint(funcSIRS,INI,T_range)
plt.plot(RES[:,0],color = 'darkblue',label = 'Susceptible',marker = '.')
plt.plot(RES[:,1],color = 'red',label = 'Infection',marker = '.')
plt.plot(RES[:,2],color = 'green',label = 'Recovery',marker = '.')
plt.title('SIRS Model')
plt.legend()
plt.xlabel('Day')
plt.ylabel('Number')
plt.show()
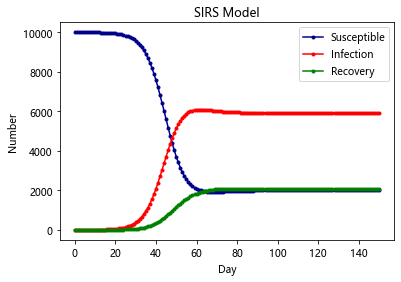
SIERS-Model
同时有潜伏期且免疫暂时的条件
import scipy.integrate as spi
import numpy as np
import matplotlib.pyplot as plt
# N为人群总数
N = 10000
# β为传染率系数
beta = 0.6
# gamma为恢复率系数
gamma = 0.1
# Ts为抗体持续时间
Ts = 7
# Te为疾病潜伏期
Te = 14
# I_0为感染者的初始人数
I_0 = 1
# E_0为潜伏者的初始人数
E_0 = 0
# R_0为治愈者的初始人数
R_0 = 0
# S_0为易感者的初始人数
S_0 = N - I_0 - E_0 - R_0
# T为传播时间
T = 150
# INI为初始状态下的数组
INI = (S_0,E_0,I_0,R_0)
def funcSEIRS(inivalue,_):
Y = np.zeros(4)
X = inivalue
# 易感个体变化
Y[0] = - (beta * X[0] * X[2]) / N + X[3] / Ts
# 潜伏个体变化
Y[1] = (beta * X[0] * X[2]) / N - X[1] / Te
# 感染个体变化
Y[2] = X[1] / Te - gamma * X[2]
# 治愈个体变化
Y[3] = gamma * X[2] - X[3] / Ts
return Y
T_range = np.arange(0,T + 1)
RES = spi.odeint(funcSEIRS,INI,T_range)
plt.plot(RES[:,0],color = 'darkblue',label = 'Susceptible',marker = '.')
plt.plot(RES[:,1],color = 'orange',label = 'Exposed',marker = '.')
plt.plot(RES[:,2],color = 'red',label = 'Infection',marker = '.')
plt.plot(RES[:,3],color = 'green',label = 'Recovery',marker = '.')
plt.title('SEIRS Model')
plt.legend()
plt.xlabel('Day')
plt.ylabel('Number')
plt.show()
数值逼近问题
一维插值
线性插值与样条插值
样例1

代码
import numpy as np
import pylab as pl
from scipy import interpolate
import matplotlib.pyplot as plt
# 设置字体以支持中文显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
x = np.linspace(0, 2*np.pi + np.pi/4,10)
y = np.sin(x)
x_new = np.linspace(0,2*np.pi+np.pi/4,100)
f_linear = interpolate.interp1d(x,y)
tck = interpolate.splrep(x,y)
y_bspline = interpolate.splev(x_new,tck)
# 可视化
plt.xlabel(u'安培/A')
plt.ylabel(u'伏特/V')
plt.plot(x, y,"o",label=u'原始数据')
plt.plot(x_new, f_linear(x_new),label=u'线性插值')
plt.plot(x_new, y_bspline,label=u'B-spline插值')
plt.legend()
plt.show()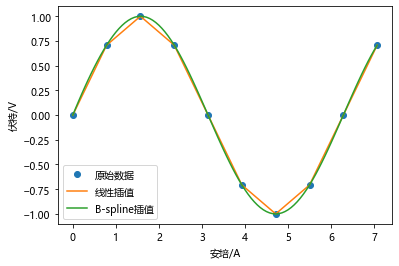
高阶样条插值
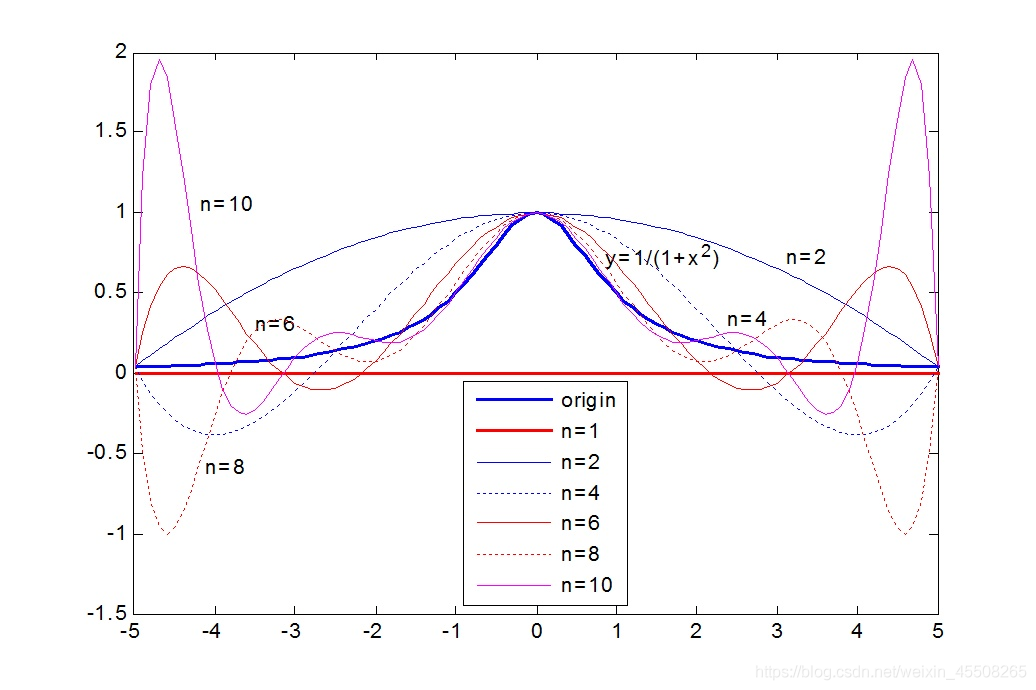
随着插值节点增多,多项式次数也增高,插值曲线在一些区域出现跳跃,并且越来越偏离原始曲线,1901 年被发现并命名为 Tolmé Runge 现象。也就是龙格现象
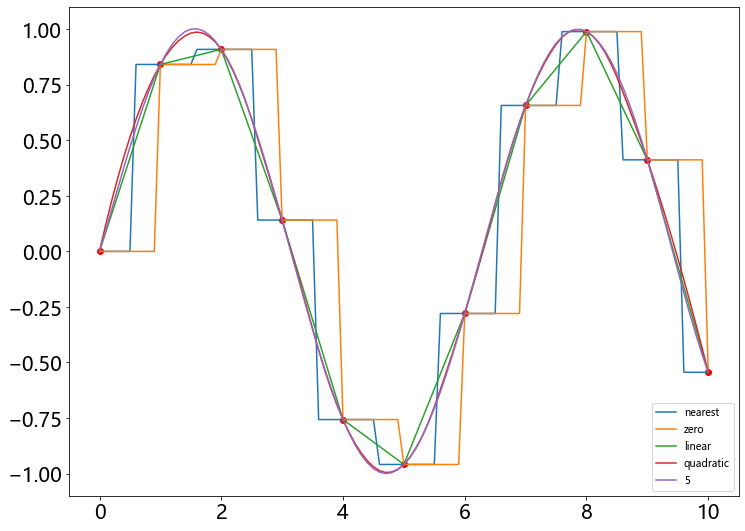
样例2
某电学元件的电压数据记录在 0~10A 范围与电流关系满足正弦函数,分别用 0-5 阶样条插值方法给出经过数据点的数值逼近函数曲线
# 创建数据点集
import numpy as np
x = np.linspace(0, 10, 11)
y = np.sin (x)
# 绘制数据点集
import pylab as pl
pl.figure(figsize =(12,9))
pl.plot(x, y, 'ro')
# 根据 kind 创建 interp1d 对象 f 、计算插值结果
xnew = np.linspace(0, 10,101)
from scipy import interpolate
for kind in ['nearest', 'zero', 'linear', 'quadratic', 5]:
f = interpolate.interp1d(x, y, kind = kind)
ynew = f(xnew)
pl.plot(xnew , ynew , label = str(kind))
pl.xticks(fontsize =20)
pl.yticks(fontsize =20)
pl.legend(loc='lower right')
pl.show()
二维插值
图像模糊处理–样条插值
样例1
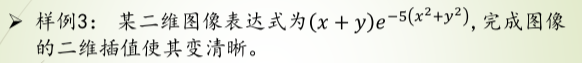
代码
import numpy as np
from scipy import interpolate
import pylab as pl
import matplotlib as mpl
def func (x,y):
return (x+y)*np.exp(-5.0*(x**2+y**2))
pl.figure(figsize =(12,9))
#X-Y 轴分为 15*15 的网格
y, x = np.mgrid[-1:1:15j, -1:1:15j]
# 计算每个网格点上函数值
fvals = func (x,y)
# 三次样条二维插值
newfunc = interpolate.interp2d(x, y, fvals , kind='cubic')
# 计算 100*100 网格上插值
xnew = np.linspace(-1,1,100)
ynew = np.linspace(-1,1,100)
fnew = newfunc(xnew ,ynew)
# 可视化
# 让 imshow 的参数 interpolation 设置为 'nearest' 方便比较插值处理
pl.subplot(121)
im1 = pl.imshow (fvals , extent = [-1,1, -1,1],
cmap = mpl.cm.hot,interpolation='nearest', origin="lower")
pl.colorbar(im1)
pl.subplot(122)
im2 = pl.imshow(fnew , extent = [-1,1, -1,1], cmap = mpl.cm.hot, interpolation='nearest', origin="lower")
pl.colorbar(im2)
pl.show()
二维插值的三维图
样例2
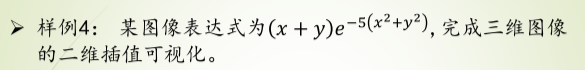
rstride 行跨度
cstride 列跨度
antialised 锯齿效果
代码
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
import matplotlib as mpl
from scipy import interpolate
import matplotlib.cm as cm
import matplotlib.pyplot as plt
def func(x, y):
return (x + y) * np.exp(-5.0 * (x ** 2 + y ** 2))
# X-Y轴分为20*20的网格
x = np.linspace(-1, 1, 20)
y = np.linspace(-1, 1, 20)
x, y = np.meshgrid(x, y) # 20*20的网格数据
fvals = func(x, y) # 计算每个网格点上的函数值 15*15的值
fig = plt.figure(figsize=(18,10)) # 设置图的大小
# Draw sub-graph1
ax = plt.subplot(1, 2, 1, projection='3d') # 设置图的位置
surf = ax.plot_surface(x, y, fvals, rstride=2, cstride=2, cmap=cm.coolwarm, linewidth=0.5,
antialiased=True) # 第四个第五个参数表示隔多少个取样点画一个小面,第六个表示画图类型,第七个是画图的线宽,第八个表示抗锯齿
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('f(x, y)') # 标签
plt.colorbar(surf, shrink=0.5, aspect=5) # 标注
# 二维插值
newfunc = interpolate.interp2d(x, y, fvals, kind='cubic') # newfunc为一个函数
# 计算100*100的网格上的插值
xnew = np.linspace(-1, 1, 100) # x
ynew = np.linspace(-1, 1, 100) # y
fnew = newfunc(xnew, ynew) # 仅仅是y值 100*100的值 np.shape(fnew) is 100*100
# print(fnew)
xnew, ynew = np.meshgrid(xnew, ynew)
ax2 = plt.subplot(1, 2, 2, projection='3d')
surf2 = ax2.plot_surface(xnew, ynew, fnew, rstride=2, cstride=2, cmap=cm.coolwarm, linewidth=0.5, antialiased=True)
ax2.set_xlabel('xnew')
ax2.set_ylabel('ynew')
ax2.set_zlabel('fnew(x, y)')
plt.colorbar(surf2, shrink=0.5, aspect=5) # 标注
plt.show()
OLS拟合
- 拟合指的是已知某函数的若干离散函数值 {f1, fn 通过调整该函数中若干待定系数 f(λ1, λ2,…, λn 使得该函数与已知点集的差别 (最小二乘意义) 最小。
- 如果待定函数是线性,就叫线性拟合或者线性回归 主要在统计中否则叫作非线性拟合或者非线性回归。表达式也可以是分段函数,这种情况下叫作样条拟合。
- 从几何意义上讲,拟合是给定了空间中的一些点,找到一个已知形式未知参数的连续曲面来最大限度地逼近这些点;而插值是找到一个( 或几个分片光滑的 连续-曲面来穿过这些点。
- 选择参数 c 使得拟合模型与实际观测值在曲线拟合各点的残差 或离差 ek = yk - f( xk,c) 的加权平方和达到最小 此时所求曲线称作在加权最小二乘意义下对数据的拟合曲线 这种方法叫做 最小二乘法 。
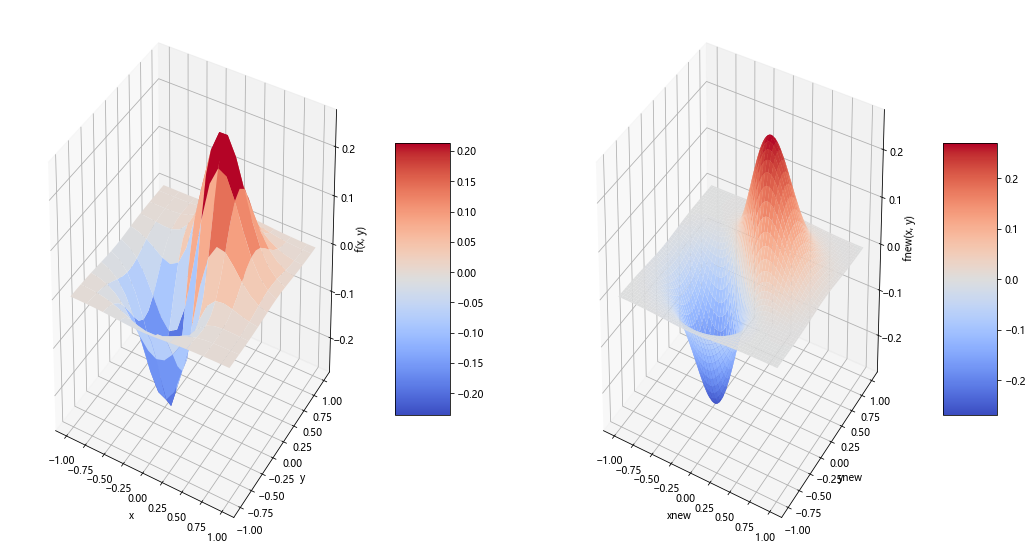
样例1

代码
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import leastsq
plt.figure(figsize =(9,9))
X=np.array([8.19, 2.72, 6.39, 8.71, 4.7, 2.66,3.78])
Y=np.array([7.01, 2.78, 6.47, 6.71, 4.1, 4.23,4.05])
# 计算以 p 为参数的直线与原始数据之间误差
def f(p):
k,b = p
return (Y-(k*X+b))
#leastsq使得 f 的输出数组的平方和最小,参数初始值为[1, 0]
r = leastsq(f, [1,0])
k, b = r[0]
plt.scatter(X, Y, s=100, alpha=1.0, marker = 'o',label = u'数据点')
x=np.linspace(0,10,1000)
y=k*x+b
ax = plt.gca()
# ax.get_xlabel(...,fontsize =20)
# ax.get_ylabel(...,fontsize =20)
plt.plot(x,y,color = 'r',linewidth=5,linestyle=':',markersize=20,label=u'拟合曲线')
plt.legend(loc=0,numpoints=1)
leg = plt.gca().get_legend()
ltext = leg.get_texts()
plt.setp(ltext,fontsize ='xx-large')
plt.xlabel(u'电流/A')
plt.ylabel(u'电压/V')
plt.xlim(0, x.max()*1.1)
plt.ylim(0, y.max()*1.1)
plt.xticks(fontsize =20)
plt.yticks(fontsize =20)
plt.legend(loc='upper left')
plt.show()
差分方程问题
递推关系-酵母菌生长模型
差分方程建模的关键在于如何得到第n组数据与第n+1组数据之间的关系
如图所示我们用培养基培养细菌时,其数量变化通常会经历这四个时期
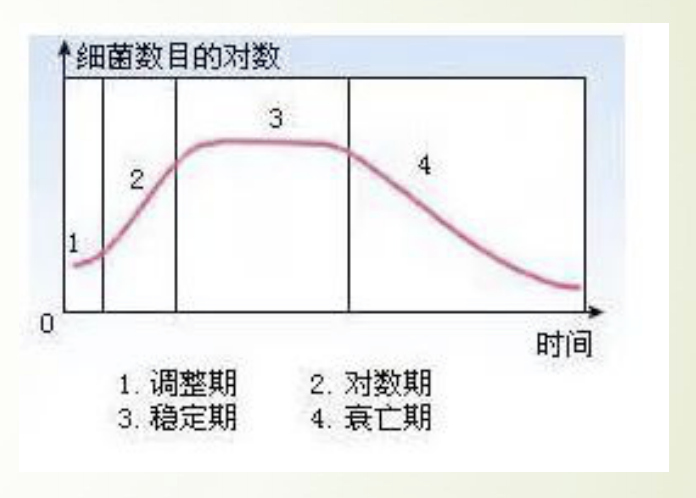
这个模型针对前三个时期建一个大致的模型:
- 调整期
- 对数期
- 稳定期
根据已有的数据进行绘图:
import matplotlib.pyplot as plt
time = [i for i in range(0,19)]
number = [9.6,18.3,29,47.2,71.1,119.1,174.6,257.3,
350.7,441.0,513.3,559.7,594.8,629.4,640.8,
651.1,655.9,659.6,661.8]
plt.title('Relationship between time and number')#创建标题
plt.xlabel('time')#X轴标签
plt.ylabel('number')#Y轴标签
plt.plot(time,number)#画图
plt.show()#显示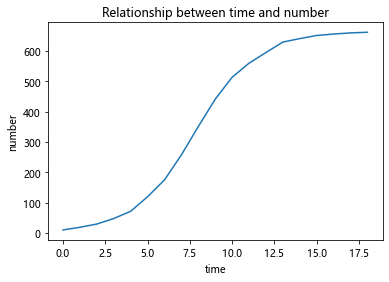
分析:
酵母菌数量增长有一个这样的规律:当某些资源只能支撑某个最大限度的种群 数量,而不能支持种群数量的无限增长,当接近这个最大值时,种群数量的增 长速度就会慢下来。
两个观测点的值差△p来表征增长速度 △p与目前的种群数量有关,数量越大,增长速度越快 △p还与剩余的未分配的资源量有关,资源越多,增长速度越快 然后以极限总群数量与现有种群数量的差值表征剩余资源量
模型:
当把该式子看成二次曲线进行拟合时:
import numpy as np
import matplotlib.pylab as plt
p_n = [9.6,18.3,29,47.2, 71.1,119.1, 174.6,
257.3, 350.7, 441.0, 513.3, 559.7, 594.8, 629.4,
640.8, 651.1, 655.9, 659.6]
delta_p = [8.7, 10.7,18.2,23.9, 48,55.5,
82.7, 93.4, 90.3, 72.3, 46.4,35.1,
34.6, 11.4, 10.3,4.8,3.7,2.2]
plt.plot(p_n,delta_p)
poly = np.polyfit(p_n, delta_p, 2)
z = np.polyval(poly,p_n)
print(poly)
plt.plot(p_n, z)
plt.show()
# [-8.01975671e-04 5.16054679e-01 6.41123361e+00]
# k = -8.01975671e-04[-8.01975671e-04 5.16054679e-01 6.41123361e+00]
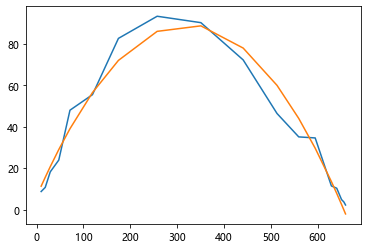
当看成一次曲线进行拟合时
将 (665 - pn) * pn 看出一个整体 那么整个式子就是一个一次函数
import numpy as np
import matplotlib.pylab as plt
p_n = [9.6,18.3,29,47.2, 71.1,119.1, 174.6,
257.3, 350.7, 441.0, 513.3, 559.7, 594.8, 629.4,
640.8, 651.1, 655.9, 659.6]
delta_p = [8.7, 10.7,18.2,23.9, 48,55.5,
82.7, 93.4, 90.3, 72.3, 46.4,35.1,
34.6, 11.4, 10.3,4.8,3.7,2.2]
p_n = np.array(p_n)
x= (665 - p_n) * p_n
plt.plot(x,delta_p)
ploy = np.polyfit(x,delta_p,1)
print(ploy)
z = np.polyval(ploy,x)
plt.plot(x,z)
plt.show()
# [ 0.00081448 -0.30791574]
# k = 0.00081448
[ 0.00081448 -0.30791574]
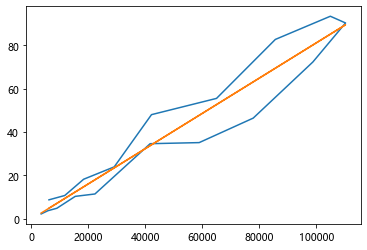
预测曲线
import matplotlib.pyplot as plt
p0 = 9.6
p_list = []
for i in range(20):
p_list.append(p0)
p0 = 0.00081448*(665-p0)*p0+p0
plt.plot(p_list)
plt.show()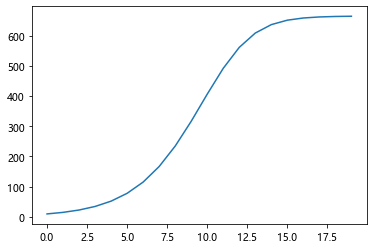
显示差分-热传导方程
一维热传导方程为:
其中,k为热传导系数,第2式是方程的初值条件,第3、4式是边值条件,热传导方程如下:
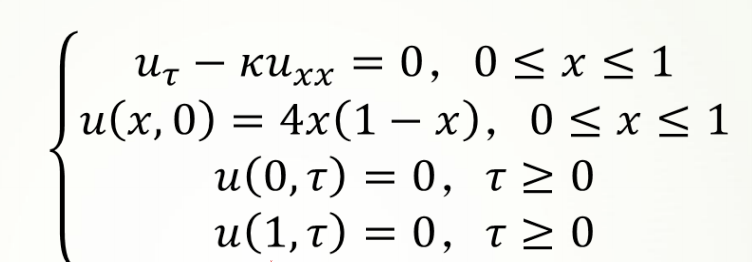
import numpy as np
import pandas as pd
import datetime
start_time = datetime.datetime.now()
np.set_printoptions(suppress=True)
def left_boundary(t): # 左边值
return np.exp(t)
def right_boundary(t): # 右边值
return np.exp(t + 1)
def initial_T(x_max, t_max, delta_x, delta_t, m, n): # 给温度T初始化
T = np.zeros((n + 1, m + 1))
for i in range(m + 1): # 初值
T[0, i] = np.exp(i * delta_x)
for i in range(1, n + 1): # 注意不包括T[0,0]与T[0,-1]
T[i, 0] = left_boundary(i * delta_t) # 左边值
T[i, -1] = right_boundary(i * delta_t) # 右边值
return T
# 一、古典显格式
def one_dimensional_heat_conduction1(T, m, n, r):
# 可以发现当r>=0.5时就发散了
for k in range(1, n + 1): # 时间层
for i in range(1, m): # 空间层
T[k, i] = (1 - 2 * r) * T[k - 1, i] + r * (T[k - 1, i - 1] + T[k - 1, i + 1])
return T.round(6)
# 二、古典隐格式(乘逆矩阵法)
def one_dimensional_heat_conduction2(T, m, n, r):
A = np.eye(m - 1, k=0) * (1 + 2 * r) + np.eye(m - 1, k=1) * (-r) + np.eye(m - 1, k=-1) * (-r)
a = np.ones(m - 1) * (-r)
a[0] = 0
b = np.ones(m - 1) * (1 + 2 * r)
c = np.ones(m - 1) * (-r)
c[-1] = 0
F = np.zeros(m - 1) # m-1个元素,索引0~(m-2)
for k in range(1, n + 1): # 时间层range(1, n + 1)
F[0] = T[k - 1, 1] + r * T[k, 0]
F[-1] = T[k - 1, m - 1] + r * T[k, m]
for i in range(1, m - 2): # 空间层
F[i] = T[k - 1, i + 1] # 给F赋值
for i in range(1, m - 1):
T[k, 1:-1] = np.linalg.inv(A) @ F # 左乘A逆
return T.round(6)
# 三、古典隐格式(追赶法)
def one_dimensional_heat_conduction3(T, m, n, r):
a = np.ones(m - 1) * (-r)
a[0] = 0
b = np.ones(m - 1) * (1 + 2 * r)
c = np.ones(m - 1) * (-r)
c[-1] = 0
F = np.zeros(m - 1) # m-1个元素,索引0~(m-2)
for k in range(1, n + 1): # 时间层range(1, n + 1)
F[0] = T[k - 1, 1] + r * T[k, 0]
F[-1] = T[k - 1, m - 1] + r * T[k, m]
y = np.zeros(m - 1)
beta = np.zeros(m - 1)
x = np.zeros(m - 1)
y[0] = F[0] / b[0]
d = b[0]
for i in range(1, m - 2): # 空间层
F[i] = T[k - 1, i + 1] # 给F赋值
for i in range(1, m - 1):
beta[i - 1] = c[i - 1] / d
d = b[i] - a[i] * beta[i - 1]
y[i] = (F[i] - a[i] * y[i - 1]) / d
x[-1] = y[-1]
for i in range(m - 3, -1, -1):
x[i] = y[i] - beta[i] * x[i + 1]
T[k, 1:-1] = x
return T.round(6)
# 四、Crank-Nicolson(乘逆矩阵法)
def one_dimensional_heat_conduction4(T, m, n, r):
A = np.eye(m - 1, k=0) * (1 + r) + np.eye(m - 1, k=1) * (-r * 0.5) + np.eye(m - 1, k=-1) * (-r * 0.5)
C = np.eye(m - 1, k=0) * (1 - r) + np.eye(m - 1, k=1) * (0.5 * r) + np.eye(m - 1, k=-1) * (0.5 * r)
for k in range(0, n): # 时间层
F = np.zeros(m - 1) # m-1个元素,索引0~(m-2)
F[0] = r / 2 * (T[k, 0] + T[k + 1, 0])
F[-1] = r / 2 * (T[k, m] + T[k + 1, m])
F = C @ T[k, 1:m] + F
T[k + 1, 1:-1] = np.linalg.inv(A) @ F
return T.round(6)
# 五、Crank-Nicolson(追赶法)
def one_dimensional_heat_conduction5(T, m, n, r):
C = np.eye(m - 1, k=0) * (1 - r) + np.eye(m - 1, k=1) * (0.5 * r) + np.eye(m - 1, k=-1) * (0.5 * r)
a = np.ones(m - 1) * (-0.5 * r)
a[0] = 0
b = np.ones(m - 1) * (1 + r)
c = np.ones(m - 1) * (-0.5 * r)
c[-1] = 0
for k in range(0, n): # 时间层
F = np.zeros(m - 1) # m-1个元素,索引0~(m-2)
F[0] = r * 0.5 * (T[k, 0] + T[k + 1, 0])
F[-1] = r * 0.5 * (T[k, m] + T[k + 1, m])
F = C @ T[k, 1:m] + F
y = np.zeros(m - 1)
beta = np.zeros(m - 1)
x = np.zeros(m - 1)
y[0] = F[0] / b[0]
d = b[0]
for i in range(1, m - 1):
beta[i - 1] = c[i - 1] / d
d = b[i] - a[i] * beta[i - 1]
y[i] = (F[i] - a[i] * y[i - 1]) / d
x[-1] = y[-1]
for i in range(m - 3, -1, -1):
x[i] = y[i] - beta[i] * x[i + 1]
T[k + 1, 1:-1] = x
return T.round(6)
def exact_solution(T, m, n, r, delta_x, delta_t): # 偏微分方程精确解
for i in range(n + 1):
for j in range(m + 1):
T[i, j] = np.exp(i * delta_t + j * delta_x)
return T.round(6)
a = 1 # 热传导系数
x_max = 1
t_max = 1
delta_x = 0.1 # 空间步长
delta_t = 0.1 # 时间步长
m = int((x_max / delta_x).__round__(4)) # 长度等分成m份
n = int((t_max / delta_t).__round__(4)) # 时间等分成n份
t_grid = np.arange(0, t_max + delta_t, delta_t) # 时间网格
x_grid = np.arange(0, x_max + delta_x, delta_x) # 位置网格
r = (a * delta_t / (delta_x ** 2)).__round__(6) # 网格比
T = initial_T(x_max, t_max, delta_x, delta_t, m, n)
print('长度等分成{}份'.format(m))
print('时间等分成{}份'.format(n))
print('网格比=', r)
# 写入到Excel文件中
p = pd.ExcelWriter('有限差分法-一维热传导-题目1.xlsx')
T1 = one_dimensional_heat_conduction1(T, m, n, r)
T1 = pd.DataFrame(T1, columns=x_grid, index=t_grid) # colums是列号,index是行号
T1.to_excel(p, '古典显格式')
T2 = one_dimensional_heat_conduction2(T, m, n, r)
T2 = pd.DataFrame(T2, columns=x_grid, index=t_grid) # colums是列号,index是行号
T2.to_excel(p, '古典隐格式(乘逆矩阵法)')
T3 = one_dimensional_heat_conduction3(T, m, n, r)
T3 = pd.DataFrame(T3, columns=x_grid, index=t_grid) # colums是列号,index是行号
T3.to_excel(p, '古典隐格式(追赶法)')
T4 = one_dimensional_heat_conduction4(T, m, n, r)
T4 = pd.DataFrame(T4, columns=x_grid, index=t_grid) # colums是列号,index是行号
T4.to_excel(p, 'Crank-Nicolson格式(乘逆矩阵法)')
T5 = one_dimensional_heat_conduction5(T, m, n, r)
T5 = pd.DataFrame(T5, columns=x_grid, index=t_grid) # colums是列号,index是行号
T5.to_excel(p, 'Crank-Nicolson格式(追赶法)')
T6 = exact_solution(T, m, n, r, delta_x, delta_t)
T6 = pd.DataFrame(T6, columns=x_grid, index=t_grid) # colums是列号,index是行号
T6.to_excel(p, '偏微分方程精确解')
p.save()
end_time = datetime.datetime.now()
print('运行时间为', (end_time - start_time))长度等分成10份
时间等分成10份
网格比= 10.0
运行时间为 0:00:00.048869
马尔科夫链-选举投票预测
马尔科夫链是由具有以下性质的一系列事件构成的过程:
- 一个事件有有限多个结果,称为状态,该过程总是这些状态中的一个;
- 在过程的每个阶段或者时段,一个特定的结果可以从它现在的状态转移到任 何状态,或者保持原状;
- 每个阶段从一个状态转移到其他状态的概率用一个转移矩阵表示,矩阵每行 的各元素在0到1之间,每行的和为1。
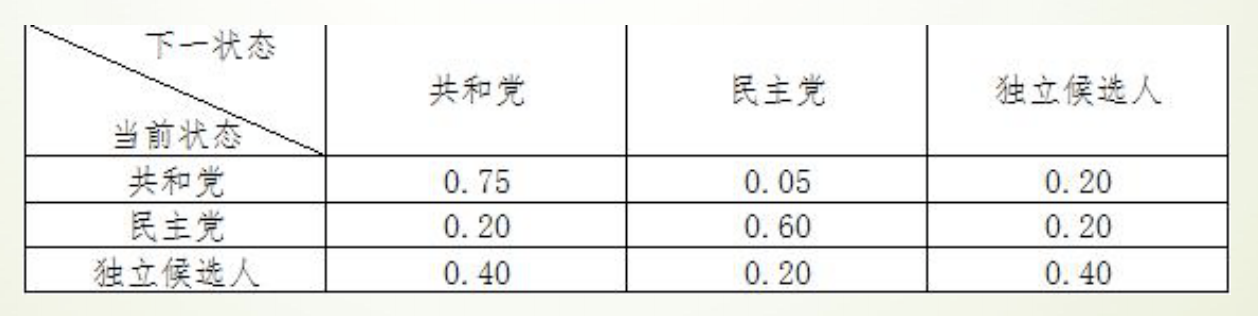
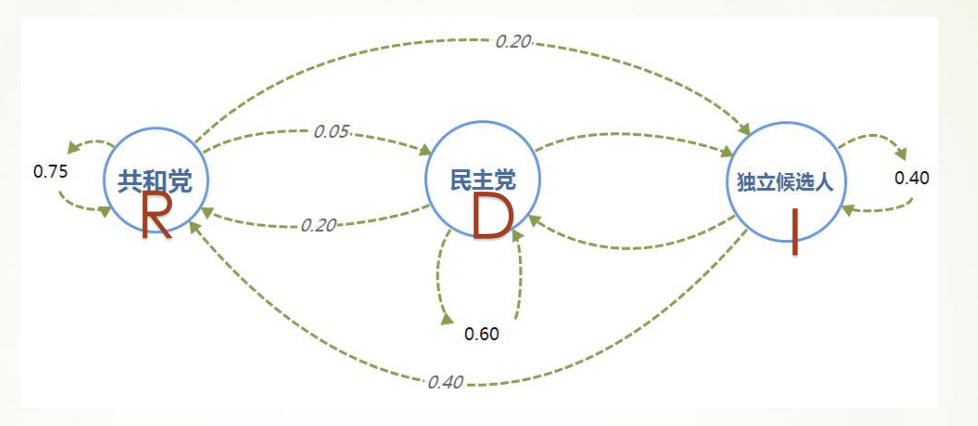
实例:选举投票预测
- 以美国大选为例,首先取得过去十次选举的历史数据,然后根据历史数据得到 选民意向的转移矩阵。
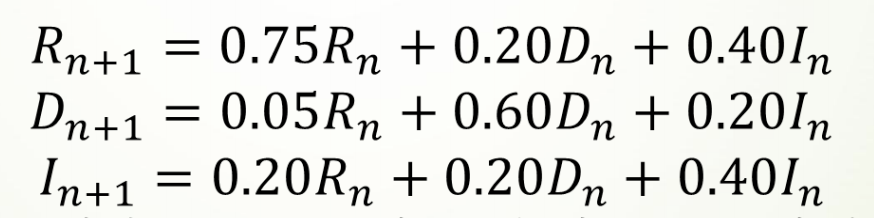
于是可以通过求解差分方程组,推测出选民投票意向的长期趋势
代码
import matplotlib.pyplot as plt
RLIST = [0.33333]
DLIST = [0.33333]
ILIST = [0.33333]
for i in range(40):
R = RLIST[i]*0.75+DLIST[i]*0.20+ILIST[i]*0.40
RLIST.append(R)
D = RLIST[i]*0.05+DLIST[i]*0.60+ILIST[i]*0.20
DLIST.append(D)
I = RLIST[i]*0.20+DLIST[i]*0.20+ILIST[i]*0.40
ILIST.append(I)
plt.plot(RLIST)
plt.plot(DLIST)
plt.plot(ILIST)
plt.xlabel('Time')
plt.ylabel('Voting percent')
plt.annotate('DemocraticParty',xy = (5,0.2))
plt.annotate('RepublicanParty',xy = (5,0.5))
plt.annotate('IndependentCandidate',xy = (5,0.25))
plt.show()
print(RLIST[-5:-1])
print(DLIST[-5:-1])
print(ILIST[-5:-1])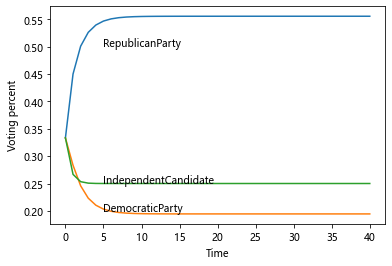
[0.5555499999214578, 0.555549999956802, 0.5555499999762412, 0.5555499999869329]
[0.19444250007854258, 0.19444250004319846, 0.1944425000237592, 0.19444250001306762]
[0.24999750000000015, 0.24999750000000015, 0.24999750000000015, 0.24999750000000015]
最后得到的长期趋势是:
- 55.55%的人选共和党
- 19.44%的人选民主党
- 25.00%的人选独立候选人
C-K方程求解
import numpy as np
a = np.array([[0.75,0.05,0.20],[0.20,0.60,0.20],[0.40,0.20,0.40]])
p = np.mat(a)
for i in range(40):
p = p*p
print(p)[[0.55557261 0.19445041 0.25000767]
[0.55557261 0.19445041 0.25000767]
[0.55557261 0.19445041 0.25000767]]
图论
图论是什么
图论〔Graph Theory〕以图为研究对象,是离散数学的重要内容。图论不仅与拓扑学、计算机数据结构和算法密切相关,而且正在成为机器学习的关键技术。
图论中所说的图,不是指图形图像(image)或地图(map),而是指由顶点(vertex)和连接顶点的边(edge)所构成的关系结构。
图提供了一种处理关系和交互等抽象概念的更好的方法,它还提供了直观的视觉方式来思考这些概念。
NetworkX 工具包
NetworkX 是基于 Python 语言的图论与复杂网络工具包,用于创建、操作和研究复杂网络的结构、动力学和功能。
NetworkX 可以以标准和非标准的数据格式描述图与网络,生成图与网络,分析网络结构,构建网络模型,设计网络算法,绘制网络图形。
NetworkX 提供了图形的类、对象、图形生成器、网络生成器、绘图工具,内置了常用的图论和网络分析算法,可以进行图和网络的建模、分析和仿真。
NetworkX 的功能非常强大和庞杂,所涉及内容远远、远远地超出了数学建模的范围,甚至于很难进行系统的概括。本系列结合数学建模的应用需求,来介绍 NetworkX 图论与复杂网络工具包的基本功能和典型算法。
图、顶点和边的创建与基本操作
图由顶点和连接顶点的边构成,但与顶点的位置、边的曲直长短无关。
Networkx 支持创建简单无向图、有向图和多重图;内置许多标准的图论算法,节点可为任意数据;支持任意的边值维度,功能丰富,简单易用。
图的基本概念
- 图(Graph):图是由若干顶点和连接顶点的边所构成关系结构。
- 顶点(Node):图中的点称为顶点,也称节点。
- 边(Edge):顶点之间的连线,称为边。
- 平行边(Parallel edge):起点相同、终点也相同的两条边称为平行边。
- 循环(Cycle):起点和终点重合的边称为循环。
- 有向图(Digraph):图中的每条边都带有方向,称为有向图。
- 无向图(Undirected graph):图中的每条边都没有方向,称为无向图。
- 赋权图(Weighted graph):图中的每条边都有一个或多个对应的参数,称为赋权图。该参数称为- 这条边的权,权可以用来表示两点间的距离、时间、费用。
- 度(Degree):与顶点相连的边的数量,称为该顶点的度。
图、顶点和边的操作
Networkx很容易创建图、向图中添加顶点和边、从图中删除顶点和边,也可以查看、删除顶点和边的属性。
图的创建
Graph() 类、DiGraph() 类、MultiGraph() 类和 MultiDiGraph() 类分别用来创建:无向图、有向图、多图和有向多图。定义和例程如下:
class Graph(incoming_graph_data=None, **attr)
import networkx as nx # 导入 NetworkX 工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot
# 创建 图
G1 = nx.Graph() # 创建:空的 无向图
G2 = nx.DiGraph() #创建:空的 有向图
G3 = nx.MultiGraph() #创建:空的 多图
G4 = nx.MultiDiGraph() #创建:空的 有向多图顶点的添加、删除和查看
图的每个顶点都有唯一的标签属性(label),可以用整数或字符类型表示,顶点还可以自定义任意属性。
顶点的常用操作:添加顶点,删除顶点,定义顶点属性,查看顶点和顶点属性。定义和例程如下:
Graph.add_node(node_for_adding, **attr)
Graph.add_nodes_from(nodes_for_adding, **attr)
Graph.remove_node(n)
Graph.remove_nodes_from(nodes)
# 顶点(node)的操作
# 向图中添加顶点
G1.add_node(1) # 向 G1 添加顶点 1
G1.add_node(1, name='n1', weight=1.0) # 添加顶点 1,定义 name, weight 属性
G1.add_node(2, date='May-16') # 添加顶点 2,定义 time 属性
G1.add_nodes_from([3, 0, 6], dist=1) # 添加多个顶点,并定义属性
G1.add_nodes_from(range(10, 15)) # 向图 G1 添加顶点 10~14
# 查看顶点和顶点属性
print(G1.nodes()) # 查看顶点列表
# [1, 2, 3, 0, 6, 10, 11, 12, 13, 14]
print(G1._node) # 查看顶点属性
# {1: {'name': 'n1', 'weight': 1.0}, 2: {'date': 'May-16'}, 3: {'dist': 1}, 0: {'dist': 1}, 6: {'dist': 1}, 10: {}, 11: {}, 12: {}, 13: {}, 14: {}}
# 从图中删除顶点
G1.remove_node(1) # 删除顶点
G1.remove_nodes_from([1, 11, 13, 14]) # 通过顶点标签的 list 删除多个顶点
print(G1.nodes()) # 查看顶点
# [2, 3, 0, 6, 10, 12] # 顶点列表[1, 2, 3, 0, 6, 10, 11, 12, 13, 14]
{1: {'name': 'n1', 'weight': 1.0}, 2: {'date': 'May-16'}, 3: {'dist': 1}, 0: {'dist': 1}, 6: {'dist': 1}, 10: {}, 11: {}, 12: {}, 13: {}, 14: {}}
[2, 3, 0, 6, 10, 12]
边的添加、删除和查看
边是两个顶点之间的连接,在 NetworkX 中 边是由对应顶点的名字的元组组成 e=(node1,node2)。边可以设置权重、关系等属性。
边的常用操作:添加边,删除边,定义边的属性,查看边和边的属性。向图中添加边时,如果边的顶点是图中不存在的,则自动向图中添加该顶点。
Graph.add_edge(u_of_edge, v_of_edge, **attr)
Graph.add_edges_from(ebunch_to_add, **attr)
Graph.add_weighted_edges_from(ebunch_to_add, weight=‘weight’, **attr)
# 边(edge)的操作
# 向图中添加边
G1.add_edge(1,5) # 向 G1 添加边,并自动添加图中没有的顶点
G1.add_edge(0,10, weight=2.7) # 向 G1 添加边,并设置边的属性
G1.add_edges_from([(1,2,{'weight':0}), (2,3,{'color':'blue'})]) # 向图中添加边,并设置属性
G1.add_edges_from([(3,6),(1,2),(6,7),(5,10),(0,1)]) # 向图中添加多条边
G1.add_weighted_edges_from([(1,2,3.6),[6,12,0.5]]) # 向图中添加多条赋权边: (node1,node2,weight)
print(G1.nodes()) # 查看顶点
# [2, 3, 0, 6, 10, 12, 1, 5, 7] # 自动添加了图中没有的顶点
# 从图中删除边
G1.remove_edge(0,1) # 从图中删除边 0-1
G1.remove_edges_from([(2,3),(1,5),(6,7)]) # 从图中删除多条边
# 查看 边和边的属性
print(G1.edges) # 查看所有的边
[(2, 1), (3, 6), (0, 10), (6, 12), (10, 5)]
print(G1.get_edge_data(1,2)) # 查看指定边的属性
# {'weight': 3.6}
print(G1[1][2]) # 查看指定边的属性
# {'weight': 3.6}
print(G1.edges(data=True)) # 查看所有边的属性
# [(2, 1, {'weight': 3.6}), (3, 6, {}), (0, 10, {'weight': 2.7}), (6, 12, {'weight': 0.5}), (10, 5, {})]
[2, 3, 0, 6, 10, 12, 1, 5, 7]
[(2, 1), (3, 6), (0, 10), (6, 12), (10, 5)]
{'weight': 3.6}
{'weight': 3.6}
[(2, 1, {'weight': 3.6}), (3, 6, {}), (0, 10, {'weight': 2.7}), (6, 12, {'weight': 0.5}), (10, 5, {})]
查看图、顶点和边的信息
# 查看图、顶点和边的信息
print(G1.nodes) # 返回所有的顶点 [node1,...]
# [2, 3, 0, 6, 10, 12, 1, 5, 7]
print(G1.edges) # 返回所有的边 [(node1,node2),...]
# [(2, 1), (3, 6), (0, 10), (6, 12), (10, 5)]
print(G1.degree) # 返回各顶点的度 [(node1,degree1),...]
# [(2, 1), (3, 1), (0, 1), (6, 2), (10, 2), (12, 1), (1, 1), (5, 1), (7, 0)]
print(G1.number_of_nodes()) # 返回顶点的数量
# 9
print(G1.number_of_edges()) # 返回边的数量
# 5
print(G1[10]) # 返回与指定顶点相邻的所有顶点的属性
# {0: {'weight': 2.7}, 5: {}}
print(G1.adj[10]) # 返回与指定顶点相邻的所有顶点的属性
# {0: {'weight': 2.7}, 5: {}}
print(G1[1][2]) # 返回指定边的属性
# {'weight': 3.6}
print(G1.adj[1][2]) # 返回指定边的属性
# {'weight': 3.6}
print(G1.degree(10)) # 返回指定顶点的度
# 2
print('nx.info:',nx.info(G1)) # 返回图的基本信息
print('nx.degree:',nx.degree(G1)) # 返回图中各顶点的度
print('nx.density:',nx.degree_histogram(G1)) # 返回图中度的分布
print('nx.pagerank:',nx.pagerank(G1)) # 返回图中各顶点的频率分布[2, 3, 0, 6, 10, 12, 1, 5, 7]
[(2, 1), (3, 6), (0, 10), (6, 12), (10, 5)]
[(2, 1), (3, 1), (0, 1), (6, 2), (10, 2), (12, 1), (1, 1), (5, 1), (7, 0)]
9
5
{0: {'weight': 2.7}, 5: {}}
{0: {'weight': 2.7}, 5: {}}
{'weight': 3.6}
{'weight': 3.6}
2
nx.info: Name:
Type: Graph
Number of nodes: 9
Number of edges: 5
Average degree: 1.1111
nx.degree: [(2, 1), (3, 1), (0, 1), (6, 2), (10, 2), (12, 1), (1, 1), (5, 1), (7, 0)]
nx.density: [1, 6, 2]
nx.pagerank: {2: 0.1226993865030675, 3: 0.11988128948774181, 0: 0.1294804066578225, 6: 0.17907377128985963, 10: 0.17907377128985968, 12: 0.06914309873160096, 1: 0.1226993865030675, 5: 0.059543981561520264, 7: 0.018404907975460127}
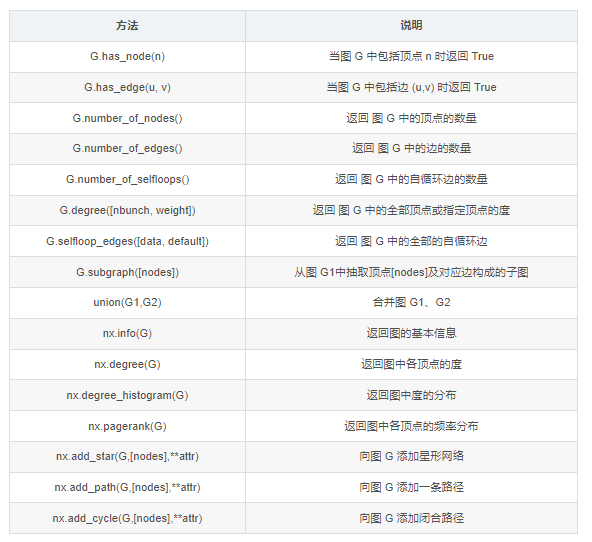
图的属性和方法
图的方法
图的绘制与分析
图的绘制
可视化是图论和网络问题中很重要的内容。NetworkX 在 Matplotlib、Graphviz 等图形工具包的基础上,提供了丰富的绘图功能。
本系列拟对图和网络的可视化作一个专题,在此只简单介绍基于 Matplotlib 的基本绘图函数。基本绘图函数使用字典提供的位置将节点放置在散点图上,或者使用布局函数计算位置。
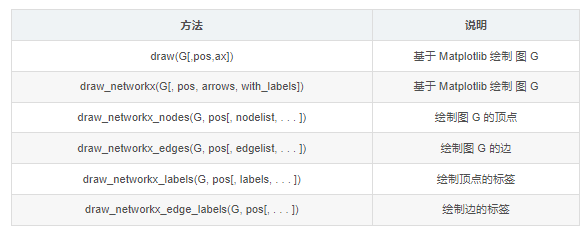
其中,nx.draw() 和 nx.draw_networkx() 是最基本的绘图函数,并可以通过自定义函数属性或其它绘图函数设置不同的绘图要求。
draw(G, pos=None, ax=None, **kwds)
draw_networkx(G, pos=None, arrows=True, with_labels=True, **kwds)
常用的属性定义如下:
- ‘node_size’:指定节点的尺寸大小,默认300
- ‘node_color’:指定节点的颜色,默认红色
- ‘node_shape’:节点的形状,默认圆形
- ‘alpha’:透明度,默认1.0,不透明
- ‘width’:边的宽度,默认1.0
- ‘edge_color’:边的颜色,默认黑色
- ‘style’:边的样式,可选 ‘solid’、‘dashed’、‘dotted’、‘dashdot’
- ‘with_labels’:节点是否带标签,默认True
- ‘font_size’:节点标签字体大小,默认12
- ‘font_color’:节点标签字体颜色,默认黑色
图的分析
NetwotkX 提供了图论函数对图的结构进行分析:
子图
- 子图是指顶点和边都分别是图 G 的顶点的子集和边的子集的图。
- subgraph()方法,按顶点从图 G 中抽出子图。例程如前。
连通子图
- 如果图 G 中的任意两点间相互连通,则 G 是连通图。
- connected_components()方法,返回连通子图的集合。
G = nx.path_graph(4)
nx.add_path(G, [7, 8, 9])
# 连通子图
listCC = [len(c) for c in sorted(nx.connected_components(G), key=len, reverse=True)]
maxCC = max(nx.connected_components(G), key=len)
print('Connected components:{}'.format(listCC)) # 所有连通子图
# Connected components:[4, 3]
print('Largest connected components:{}'.format(maxCC)) # 最大连通子图
# Largest connected components:{0, 1, 2, 3}
Connected components:[4, 3]
Largest connected components:{0, 1, 2, 3}
回归问题
线性回归分析
Python固定导入的包
# 工具:python3
#固定导入
import numpy as np #科学计算基础库,多维数组对象ndarray
import pandas as pd #数据处理库,DataFrame(二维数组)
import matplotlib as mpl #画图基础库
import matplotlib.pyplot as plt #最常用的绘图库
from scipy import stats #scipy库的stats模块
mpl.rcParams["font.family"]="SimHei" #使用支持的黑体中文字体
mpl.rcParams["axes.unicode_minus"]=False # 用来正常显示负号 "-"
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
# % matplotlib inline #jupyter中用于直接嵌入图表,不用plt.show()
import warnings
warnings.filterwarnings("ignore") #用于排除警告
#用于显示使用库的版本
print("numpy_" + np.__version__)
print("pandas_" + pd.__version__)
print("matplotlib_"+ mpl.__version__)numpy_1.20.1
pandas_1.2.4
matplotlib_3.2.2
线性回归
Y= aX + b + e ,e表示残差
线性回归:分析结论的前提:数据满足统计假设
- 正态性:预测变量固定时,因变量正态分布
- 独立性:因变量互相独立
- 线性:因变量与自变量线性(残差白噪声)
- 同方差性:残差方差均匀
scipy.optimize.curve_fit():回归函数拟合
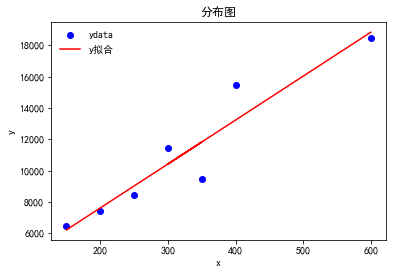
from scipy.optimize import curve_fit #回归函数拟合包
def func(x,a,b):
y = a*x + b
return y
x= np.array([150,200,250,350,300,400,600])
ydata=np.array([6450,7450,8450,9450,11450,15450,18450])
popt,pcov=curve_fit(func,x,ydata)
print(curve_fit(func,x,ydata)) #拟合函数 y = 28.03191489*x + 2011.17021277
plt.title('分布图')
plt.xlabel('x')
plt.ylabel('y')
plt.plot(x,ydata,'bo',x,func(x,popt[0],popt[1]),'r-')
plt.legend(["ydata","y拟合"],loc="best", frameon=False, ncol=1)
plt.show() (array([ 28.03191489, 2011.17021277]), array([[ 18.16149846, -5837.62445922],
[ -5837.62445922, 2224783.5263512 ]]))
scipy.stats.linregress(): 线性拟合
from scipy import stats #线性回归包
x= np.array([150,200,250,350,300,400,600])
ydata=np.array([6450,7450,8450,9450,11450,15450,18450])
slope, intercept, r_value, p_value, std_err = stats.linregress(x,ydata)
#a , b r , p , 标准误
print(stats.linregress(x,ydata))
y = slope*x + intercept #拟合函数
plt.title('分布图')
plt.xlabel('x')
plt.ylabel('y')
plt.plot(x,ydata,'bo',x,func(x,popt[0],popt[1]),'r-')
plt.legend(["ydata","y拟合"],loc="best", frameon=False, ncol=1)
plt.show() LinregressResult(slope=28.03191489361702, intercept=2011.1702127659555, rvalue=0.9467887456768281, pvalue=0.0012189021752212815, stderr=4.261630957224319, intercept_stderr=1491.5708350285115)
statsmodels.formula.api.OLS():普通最小二乘模型拟合- - 常用
np.random.seed(123456789)
N = 100
x1 = np.random.randn(N) # 自变量
x2 = np.random.randn(N)
data = pd.DataFrame({"x1": x1, "x2": x2})
def y_true(x1, x2):
return 1 + 2 * x1 + 3 * x2 + 4 * x1 * x2
data["y_true"] = y_true(x1, x2) # 因变量
e = np.random.randn(N) # 标准正态分布
data["y"] = data["y_true"] + e # 加些噪音,加些扰动,噪音是符合标准正态分布的
data.head(3)
import statsmodels.formula.api as sm #statsmodels.formula.api.ols 回归模型库
model = sm.ols("y ~x1 + x2", data) # 这里没有写截距,截距是默认存在的
# model = sm.ols("y ~ -1 + x1 + x2", data) # 这里加上-1,表示不加截距
result = model.fit()
print(result.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.380
Model: OLS Adj. R-squared: 0.367
Method: Least Squares F-statistic: 29.76
Date: Sun, 17 Oct 2021 Prob (F-statistic): 8.36e-11
Time: 22:28:41 Log-Likelihood: -271.52
No. Observations: 100 AIC: 549.0
Df Residuals: 97 BIC: 556.9
Df Model: 2
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.9868 0.382 2.581 0.011 0.228 1.746
x1 1.0810 0.391 2.766 0.007 0.305 1.857
x2 3.0793 0.432 7.134 0.000 2.223 3.936
==============================================================================
Omnibus: 19.951 Durbin-Watson: 1.682
Prob(Omnibus): 0.000 Jarque-Bera (JB): 49.964
Skew: -0.660 Prob(JB): 1.41e-11
Kurtosis: 6.201 Cond. No. 1.32
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
回归诊断流程
import numpy as np
import pandas as pd
from sklearn.linear_model import BayesianRidge, LinearRegression, ElasticNet
from sklearn.svm import SVR
from sklearn.ensemble import GradientBoostingRegressor # 集成算法
from sklearn.model_selection import cross_val_score # 交叉验证
from sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squared_error, r2_score
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 数据导入
df = pd.read_csv('data/train.csv',
usecols=['lstat', 'indus', 'nox', 'rm', 'medv'])
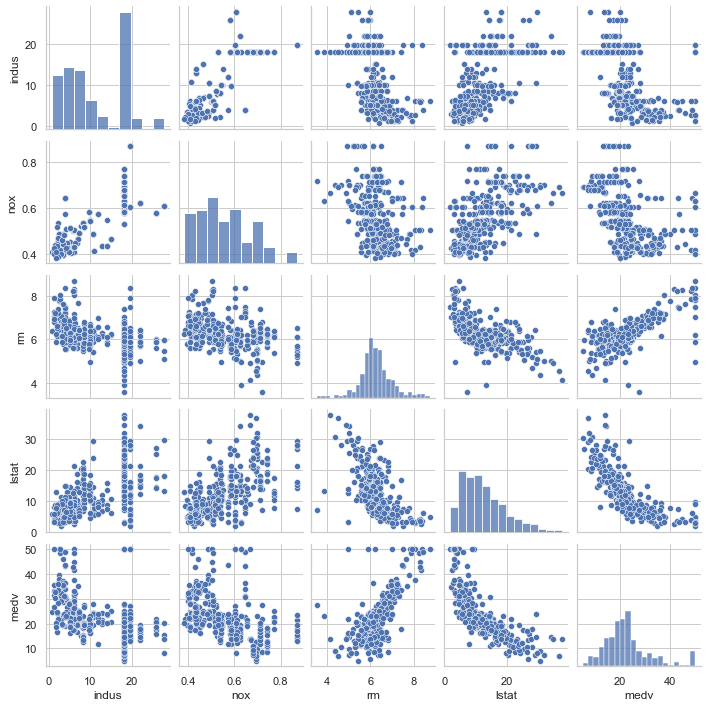
# 可视化数据关系
sns.set(style='whitegrid', context='notebook') #style控制默认样式,context控制着默认的画幅大小
sns.pairplot(df, size=2)
plt.savefig('x.png')
# 相关度
corr = df.corr()
# 相关度热力图
sns.heatmap(corr, cmap='GnBu_r', square=True, annot=True)
plt.savefig('xx.png')
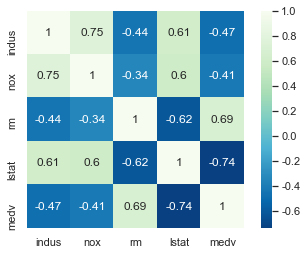
可见自变量lstat与因变量medv强负相关,自变量rm与因变量medv强正相关
# 自变量
X = df[['lstat', 'rm']].values
# 因变量
y = df[df.columns[-1]].values
# 设置交叉验证次数
n_folds = 5
# 建立贝叶斯岭回归模型
br_model = BayesianRidge()
# 普通线性回归
lr_model = LinearRegression()
# 弹性网络回归模型
etc_model = ElasticNet()
# 支持向量机回归
svr_model = SVR()
# 梯度增强回归模型对象
gbr_model = GradientBoostingRegressor()
# 不同模型的名称列表
model_names = ['BayesianRidge', 'LinearRegression', 'ElasticNet', 'SVR', 'GBR']
# 不同回归模型
model_dic = [br_model, lr_model, etc_model, svr_model, gbr_model]
# 交叉验证结果
cv_score_list = []
# 各个回归模型预测的y值列表
pre_y_list = []
# 读出每个回归模型对象
for model in model_dic:
# 将每个回归模型导入交叉检验
scores = cross_val_score(model, X, y, cv=n_folds)
# 将交叉检验结果存入结果列表
cv_score_list.append(scores)
# 将回归训练中得到的预测y存入列表
pre_y_list.append(model.fit(X, y).predict(X))
### 模型效果指标评估 ###
# 获取样本量,特征数
n_sample, n_feature = X.shape
# 回归评估指标对象列表
model_metrics_name = [explained_variance_score, mean_absolute_error, mean_squared_error, r2_score]
# 回归评估指标列表
model_metrics_list = []
# 循环每个模型的预测结果
for pre_y in pre_y_list:
# 临时结果列表
tmp_list = []
# 循环每个指标对象
for mdl in model_metrics_name:
# 计算每个回归指标结果
tmp_score = mdl(y, pre_y)
# 将结果存入临时列表
tmp_list.append(tmp_score)
# 将结果存入回归评估列表
model_metrics_list.append(tmp_list)
df_score = pd.DataFrame(cv_score_list, index=model_names)
df_met = pd.DataFrame(model_metrics_list, index=model_names, columns=['ev', 'mae', 'mse', 'r2'])
# 各个交叉验证的结果
df_score| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| BayesianRidge | 0.592068 | 0.647307 | 0.264133 | 0.149150 | -0.648919 |
| LinearRegression | 0.601070 | 0.651541 | 0.308329 | 0.142842 | -0.672901 |
| ElasticNet | 0.382249 | 0.552730 | 0.003601 | 0.421609 | -0.077382 |
| SVR | 0.617085 | 0.520500 | -0.301541 | 0.473345 | 0.266060 |
| GBR | 0.356270 | 0.815895 | 0.562909 | 0.512857 | 0.060558 |
# 各种评估结果
df_met| ev | mae | mse | r2 | |
|---|---|---|---|---|
| BayesianRidge | 0.634281 | 3.895336 | 30.683785 | 0.634281 |
| LinearRegression | 0.634334 | 3.888380 | 30.679309 | 0.634334 |
| ElasticNet | 0.586648 | 4.213199 | 34.680158 | 0.586648 |
| SVR | 0.628395 | 3.701105 | 32.394854 | 0.613886 |
| GBR | 0.934846 | 1.716812 | 5.466391 | 0.934846 |
### 可视化 ###
# 创建画布
plt.figure(figsize=(9, 6))
# 颜色列表
color_list = ['r', 'g', 'b', 'y', 'c']
# 循环结果画图
for i, pre_y in enumerate(pre_y_list):
# 子网络
plt.subplot(2, 3, i+1)
# 画出原始值的曲线
plt.plot(np.arange(X.shape[0]), y, color='k', label='y')
# 画出各个模型的预测线
plt.plot(np.arange(X.shape[0]), pre_y, color_list[i], label=model_names[i])
plt.title(model_names[i])
plt.legend(loc='lower left')
plt.savefig('xxx.png')
plt.show()
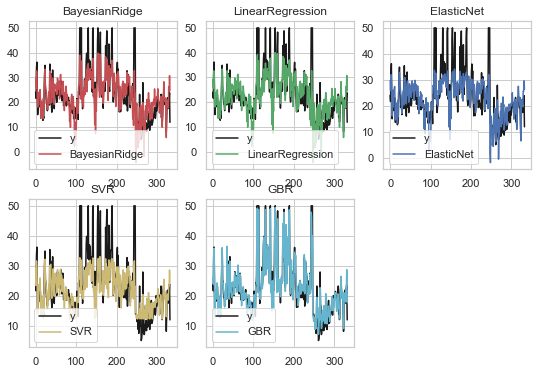
以上可见梯度增强回归(GBR)是所有模型中拟合效果最好的
评估指标解释:
- explained_variance_score:解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因变量的方差变化,值越小则说明效果越差。
- mean_absolute_error:平均绝对误差(Mean Absolute Error, MAE),用于评估预测结果和真实数据集的接近程度的程度,其值越小说明拟合效果越好。
- mean_squared_error:均方差(Mean squared error, MSE),该指标计算的是拟合数据和原始数据对应样本点的误差的平方和的均值,其值越小说明拟合效果越好。
- r2_score:判定系数,其含义是也是解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因变量的方差变化,值越小则说明效果越差。
logistic回归
鸢尾花数据集
鸢尾花有三个亚属,分别是山鸢尾(Iris-setosa)、变色鸢尾(Iris- versicolor)和维吉尼亚鸢尾(Iris-virginica)。
该数据集一共包含4个特 征变量,1个类别变量。共有150个样本,iris是鸢尾植物,这里存储了其萼片 和花瓣的长宽,共4个属性,鸢尾植物分三类。
绘制散点图
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
#获取花卉两列数据集
DD = iris.data
X = [x[0] for x in DD]
Y = [x[1] for x in DD]
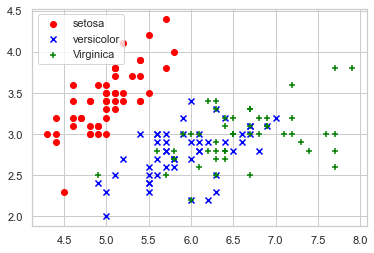
plt.scatter(X[:50], Y[:50], color='red', marker='o', label='setosa')
plt.scatter(X[50:100], Y[50:100], color='blue', marker='x', label='versicolor')
plt.scatter(X[100:], Y[100:],color='green', marker='+', label='Virginica')
plt.legend(loc=2) #左上角
plt.show()
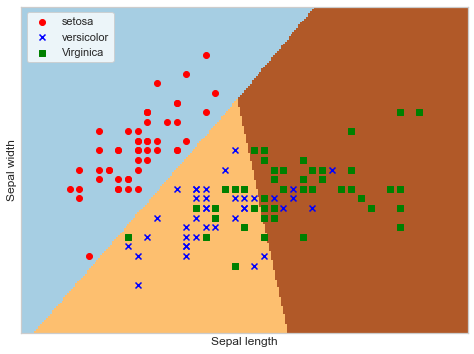
逻辑回归分析
from sklearn.linear_model import LogisticRegression
iris = load_iris()
X = iris.data[:, :2] #获取花卉两列数据集
Y = iris.target
lr = LogisticRegression(C=1e5)
lr.fit(X,Y)
#meshgrid函数生成两个网格矩阵
h = .02
x_min, x_max = X[:, 0].min()-.5, X[:, 0].max()+.5
y_min, y_max = X[:, 1].min()-.5, X[:, 1].max()+.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
Z = lr.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.figure(1, figsize=(8,6))
plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired)
plt.scatter(X[:50,0], X[:50,1], color='red',marker='o', label='setosa')
plt.scatter(X[50:100,0], X[50:100,1], color='blue', marker='x', label='versicolor')
plt.scatter(X[100:,0], X[100:,1], color='green', marker='s', label='Virginica')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.xticks(())
plt.yticks(())
plt.legend(loc=2)
plt.show()
蒙特卡洛算法
基本思想
当所求解问题是某种随机事件出现的概率,或者是某个随机变量的期望值时,通过某种“实验”的方法,以这种事件出现的频率估计这一随机事件的概率,或者得到这个随机变量的某些数字特征,并将其作为问题的解。
工作步骤:
构造或描述概率过程
实现从已知概率分布抽样
建立各种估计量
样例1
题目:经典的蒙特卡洛方法求圆周率
基本思想:在图中区域产生足够多的随机数点,然后计算落在圆内的点的个数与总个数的比值再乘以4,就是圆周率。
代码
模拟10000,100000,10000000次
import math
import random
def calc_pi(m):
n=0
for i in range(m):
# x、y为0-1之间的随机数
x = random.random()
y = random.random()
# 若点(x,y) 属于图中1/4圆内 则有效个数+1
if math.sqrt(x**2 + y**2) < 1:
n += 1
# 计算pi
pi = 4 * n / m
print("pi = {}".format(pi))
calc_pi(10000)
calc_pi(100000)
calc_pi(1000000)pi = 3.1456
pi = 3.13804
pi = 3.140816
样例2
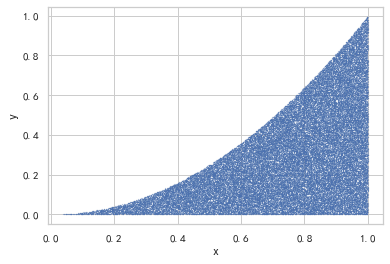
计算函数y = x^2在[0,1]区间的定积分
代码
import matplotlib.pyplot as plt
import numpy as np
import math
import random
# 这两行代码解决 plt 中文显示的问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
m = 200000
n = 0
a = np.array([])
b = np.array([])
flag = 1
for i in range(m):
x = random.random()
y = random.random()
if y <= x**2:
n += 1
a = np.append(a,x)
b = np.append(b,y)
r = n / m
print("r = {}".format(r))
plt.scatter(a, b, s=0.1,marker=".") # 画散点图,大小为 0.1
plt.xlabel('x') # 横坐标轴标题
plt.ylabel('y') # 纵坐标轴标题
plt.show()r = 0.33264
样例3
变式:计算积分
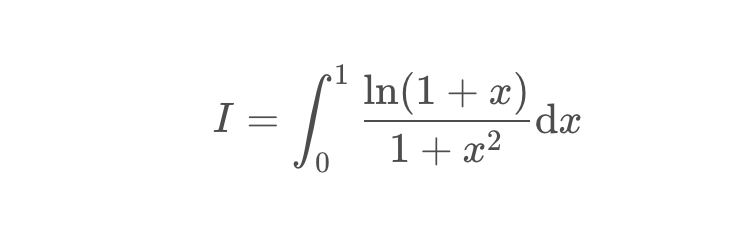
代码
绘制函数图像
import numpy as np
import matplotlib.pylab as plt
x = np.linspace(0,1,num=1000)
y = np.log(1 + x) / (1 + x**2)
plt.plot(x,y,'.')
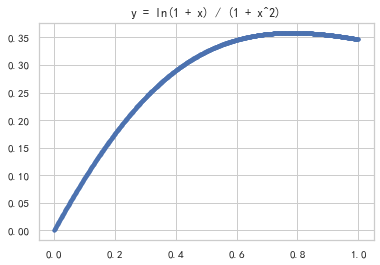
plt.title('y = ln(1 + x) / (1 + x^2)')
plt.show()
计算积分
import numpy as np
import random
m = 1000000
n = 0
for i in range(m):
x = random.random()
y = random.random()
if np.log(1 + x) / (1 + x**2) > y:
n += 1
ans = n / m
print("实验值 = {}".format(ans))
print("理论值 = {}".format(np.pi/8*np.log(2)))实验值 = 0.272536
理论值 = 0.27219826128795027
样例4
现在有个项目,共三个WBS要素,分别是设计、建造和测试
假设这三个WBS要素预估工期的概率分布呈标准正态分布,且三者之间都是完成到开始的逻辑关系
于是整个项目工期就是三个WBS要素工期之和
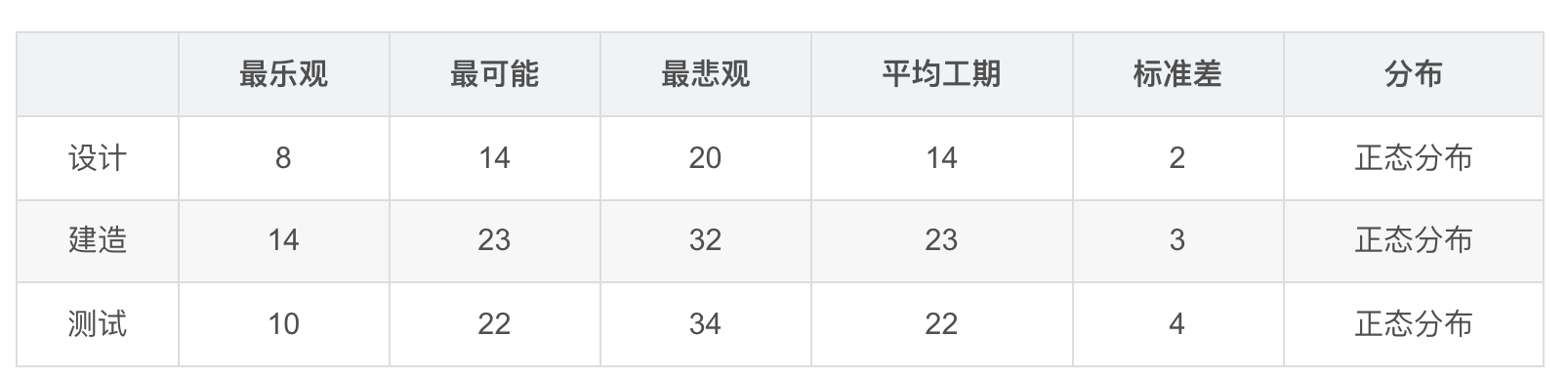
首先,先画出这三个要素的概率密度函数
从表中可以看出 时间最少为8天 最长为34天 所以我们设置时间范围为7-35 天
代码
import numpy as np
import matplotlib.pyplot as plt
import math
import latexify #引入latexify模块
@latexify.with_latex #特定语法,表示之后定义的函数可以转化为LaTeX代码
def NormalDistribution(x, mean, sigma):
return np.exp(-1*((x-mean)**2)/(2*(sigma**2)))/(math.sqrt(2*np.pi) * sigma)
mean1, sigma1 = 14, 2
x1 = np.linspace(7, 35,num=100)
mean2, sigma2 = 23, 3
x2 = np.linspace(7, 35, num=100)
mean3, sigma3 =22, 4
x3 = np.linspace(7, 35, num=100)
y1 = NormalDistribution(x1, mean1, sigma1)
y2 = NormalDistribution(x2, mean2, sigma2)
y3 = NormalDistribution(x3, mean3, sigma3)
plt.plot(x1, y1, 'r', label='m=14,sig=2')
plt.plot(x2, y2, 'g', label='m=23,sig=3')
plt.plot(x3, y3, 'b', label='m=22,sig=4')
plt.legend()
plt.grid()
plt.show()
NormalDistribution
import numpy as np
import matplotlib.pylab as plt
import random
import math
m = 10000
a = 0
b = 0
y1 = np.random.normal(loc=14,scale=2,size=m)
y2 = np.random.normal(loc=23,scale=3,size=m)
y3 = np.random.normal(loc=22,scale=4,size=m)
y =y1 + y2 + y3
a,b = np.mean(y),np.var(y)
print('实验值:\n',a,b)
print('理论值:\n均值为59 = 14 + 23 + 22\n方差为29 = 2*2 + 3*3 + 4*4')
实验值:
59.092510534230925 28.867667234563722
理论值:
均值为59 = 14 + 23 + 22
方差为29 = 2*2 + 3*3 + 4*4
三门问题
简介
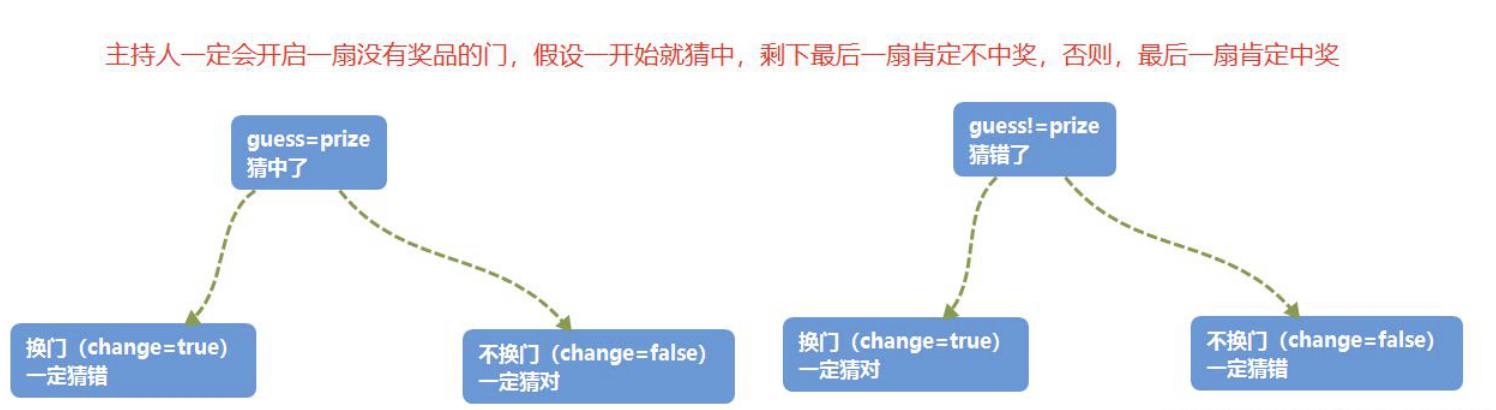
三门问题(Monty Hall probelm)亦称为蒙提霍尔问题,出自美国电视游戏节目Let’s Make a Deal。
参赛者会看见三扇关闭了的门,其中一扇的后面有一辆汽车,选中后面有车的那扇门可赢得该汽车,另外两扇门则各藏有一只山羊。
当参赛者选定了一扇门,但未去开启它的时候,节目主持人开启剩下两扇门的其中一扇,露出其中一只山羊。主持人其后问参赛者要不要换另一扇仍然关上的门。
问题是:换另一扇门是否会增加参赛者赢得汽车的几率?如果严格按照上述条件,即主持人清楚地知道,自己打开的那扇门后面是羊,那么答案是会。不换门的话,赢得汽车的几率是1/3,,换门的话,赢得汽车的几率是2/3
蒙特卡洛思想的应用
应用蒙特卡洛重点在使用随机数来模拟类似于赌博问题的赢率问题,并且通过多次模拟得到所要计算值的模拟值。
在三门问题中,用0、1、2分代表三扇门的编号,在[0,2]之间随机生成一个整数代表奖品所在门的编号prize,再次在[0,2]之间随机生成一个整数代表参赛者所选择的门的编号guess。用变量change代表游戏中的换门(true)与不换门(false)
蒙特卡洛过程
代码
import math
def play(change):
prize = random.randint(0,2)
guess = random.randint(0,2)
if guess == prize:
if change:
return False
else:
return True
else:
if change:
return True
else:
return False
def winRate(change, N):
win = 0
for i in range(N):
if(play(change)):
win += 1
print("中奖率为{}".format(win / N))
N = 1000000
print("每次换门的中奖概率:")
winRate(True,N)
print("每次都不换门的中奖概率:")
winRate(False,N)
# 理论换门2/3 不换门1/3
#每次换门的中奖概率:
#中奖率为0.665769
#每次都不换门的中奖概率:
#中奖率为0.33292每次换门的中奖概率:
中奖率为0.666426
每次都不换门的中奖概率:
中奖率为0.333371
M*M豆问题
简介
M*M豆贝叶斯统计问题
M&M豆是有各种颜色的糖果巧克力豆。制造M&M豆的Mars公司会不时变更不同颜色巧克力豆之间的混合比例。
1995年,他们推出了蓝色的M&M豆。在此前一袋普通的M&M豆中,颜色的搭配为:30%褐色,20%黄色,20%红色,10%绿色,10%橙色,10%黄褐色。这之后变成了:24%蓝色,20%绿色,16%橙色,14%黄色,13%红色,13%褐色。
假设我的一个朋友有两袋M&M豆,他告诉我一袋是1994年,一带是1996年。
但他没告诉我具体那个袋子是哪一年的,他从每个袋子里各取了一个M&M豆给我。一个是黄色,一个是绿色的。那么黄色豆来自1994年的袋子的概率是多少?
代码
import time
import random
for i in range(10):
print(time.strftime("%Y-%m-%d %X",time.localtime()))
dou = {1994:{'褐色':30,'黄色':20,'红色':20,'绿色':10,'橙色':10,'黄褐':30},
1996:{'蓝色':24,'绿色':20,'橙色':16,'黄色':14,'红色':13,'褐色':13}}
num = 10000
list_1994 = ['褐色']*30*num+['黄色']*20*num+['红色']*20*num+['绿色']*10*num+['橙色']*10*num+['黄褐']*10*num
list_1996 = ['蓝色']*24*num+['绿色']*20*num+['橙色']*16*num+['黄色']*14*num+['红色']*13*num+['褐色']*13*num
random.shuffle(list_1994)
random.shuffle(list_1996)
count_all = 0
count_key = 0
for key in range(100 * num):
if list_1994[key] == '黄色' and list_1996[key] == '绿色':
count_all += 1
count_key += 1
if list_1994[key] == '绿色' and list_1996[key] == '黄色':
count_all += 1
print(count_key / count_all,20/27,"delta = {}".format(count_key/count_all-20/27))
# print(time.strftime("%Y-%m-%d %X",time.localtime()))2021-10-17 22:28:58
0.7416881216544111 0.7407407407407407 delta = 0.0009473809136704148
2021-10-17 22:28:59
0.7407544515603598 0.7407407407407407 delta = 1.3710819619094927e-05
2021-10-17 22:29:00
0.7404688828902118 0.7407407407407407 delta = -0.000271857850528856
2021-10-17 22:29:01
0.7417392429873708 0.7407407407407407 delta = 0.0009985022466301174
2021-10-17 22:29:02
0.7426368371299883 0.7407407407407407 delta = 0.0018960963892475924
2021-10-17 22:29:03
0.7396181561548176 0.7407407407407407 delta = -0.0011225845859230699
2021-10-17 22:29:04
0.7407215541165587 0.7407407407407407 delta = -1.9186624181988243e-05
2021-10-17 22:29:05
0.7407250018476091 0.7407407407407407 delta = -1.5738893131556075e-05
2021-10-17 22:29:06
0.7417678601042953 0.7407407407407407 delta = 0.001027119363554596
2021-10-17 22:29:07
0.739666276889953 0.7407407407407407 delta = -0.001074463850787688
补充(有待完善)
最后补充一些LaTeX公式在Python中的写法
@latexify.with_latex 特定语法,表示之后定义的函数可以转化为LaTeX代码
def f(x,y,z): 包含的参数
pass #此处填写可能需要的数学表达式
return result #也可以直接体现数学关系
print(f) #print(函数名)
首先,导入需要的库(math,latexify)
核心,在需要转变的数学表达式写在自定义函数中,并在之前加上特有语法
@latexify.with_latex
在print()函数中加入函数名,即可在输出区得到需要的LaTeX数学表达式
特别说明,生成的表达式为定义式,如果只需要等式,可以把生成表达式中的triangleq改成=
说明:为了不在LaTeX编译时报错,故不输出公式
(注释后仍然报错,暂未知原因)
例1 根式
import latexify #引入latexify模块
@latexify.with_latex #特定语法,表示之后定义的函数可以转化为LaTeX代码
def solve(a,b,c):
return (-b+math.sqrt(b**2-4*a*c))/(2*a)
print(solve)
solve\mathrm{solve}(a, b, c)\triangleq \frac{-b + \sqrt{b^{2} - 4ac}}{2a}
将得到的式子中的triangeleq改为=,可以得到等式(在LaTeX中可用,暂不知如何在Python控制台输出)
例2 分段函数
@latexify.with_latex
def sinc(x):
if x == 0:
return 1
else:
return math.sin(x) / x
print(sinc)
sinc\mathrm{sinc}(x)\triangleq \left\{ \begin{array}{ll} 1, & \mathrm{if} \ x=0 \\ \frac{\sin{\left({x}\right)}}{x}, & \mathrm{otherwise} \end{array} \right.
@latexify.with_latex
def fib(x):
if x == 0:
return 1
elif x == 1:
return 1
else:
return fib(x-1)+fib(x-2)
print(fib)
fib\mathrm{fib}(x)\triangleq \left\{ \begin{array}{ll} 1, & \mathrm{if} \ x=0 \\ 1, & \mathrm{if} \ x=1 \\ \mathrm{fib}\left(x - 1\right) + \mathrm{fib}\left(x - 2\right), & \mathrm{otherwise} \end{array} \right.
例3 对数
import math
import latexify
@latexify.with_latex
def f(x,y):
return math.log2(x+y)
print(f)
f\mathrm{f}(x, y)\triangleq \log_{2}{\left({x + y}\right)}
例4 绝对值
import math
import latexify
@latexify.with_latex
def f(x):
return abs(x)
print(f)
f\mathrm{f}(x)\triangleq \left|{x}\right|
例5 希腊字母
@latexify.with_latex
def f_3(alpha, beta, gamma, Omega):
return alpha * beta + math.gamma(gamma) + Omega
print(f_3)
f_3\mathrm{f_3}({\alpha}, {\beta}, {\gamma}, {\Omega})\triangleq {\alpha}{\beta} + \Gamma\left({{\gamma}}\right) + {\Omega}
@latexify.with_latex
# 注意pi不要写成math.pi
def f_4(x,y):
return A*cos(omega*pi*x) +B*sin(mu*pi*y)
print(f_4)
f_4\mathrm{f_4}(x, y)\triangleq A\mathrm{cos}\left({\omega}{\pi}x\right) + B\mathrm{sin}\left({\mu}{\pi}y\right)
时间序列问题
- 时间戳(timestamp)
- 固定周期(period)
- 时间间隔(interval)
JetRail高铁乘客量预测——7种时间序列方法
内容简介
时间序列预测在日常分析中常会用到,是重要的时序数据处理方法。
高铁客运量预测
假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量。
数据获取:获得2012-2014两年每小时乘客数量
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df = pd.read_csv('data/jetrail_train.csv')
print(df.head())
print(df.shape)
ID Datetime Count
0 0 25-08-2012 00:00 8
1 1 25-08-2012 01:00 2
2 2 25-08-2012 02:00 6
3 3 25-08-2012 03:00 2
4 4 25-08-2012 04:00 2
(18288, 3)
数据集处理:(以每天为单位构造和聚合数据集)
- 从2012年8月—2013年12月的数据中构造一个数据集
- 创建train and test文件用于建模。前14个月(2012年8月—2013年10月)用作训练数据,后两个月(2013年11月—2013年12月)用作测试数据。
- 以每天为单位聚合数据集
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('data/jetrail_train.csv',nrows=11856)
train = df[0:10392]
test = df[10392:]
df['Timestamp'] = pd.to_datetime(df['Datetime'], format='%d-%m-%Y %H:%M') # 4位年用Y,2位年用y
df.index = df['Timestamp']
df = df.resample('D').mean() #按天采样,计算均值
train['Timestamp'] = pd.to_datetime(train['Datetime'], format='%d-%m-%Y %H:%M')
train.index = train['Timestamp']
train = train.resample('D').mean()
test['Timestamp'] = pd.to_datetime(test['Datetime'], format='%d-%m-%Y %H:%M')
test.index = test['Timestamp']
test = test.resample('D').mean()
train.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14)
test.Count.plot(figsize=(15,8), title= 'Daily Ridership', fontsize=14)
plt.show()
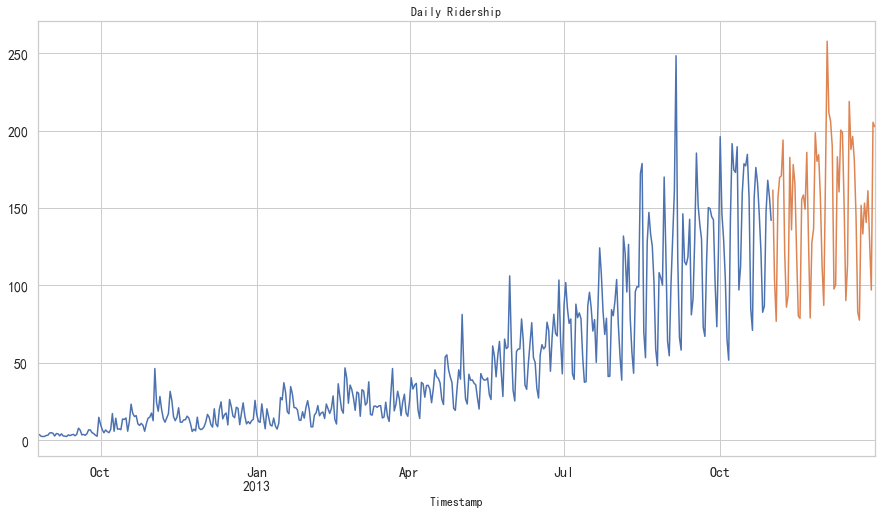
朴素法
 如果数据集在一段时间内都很稳定,我们想预测第二天的价格,可以取前面一天的价格,预测第二天的值。这种假设第一个预测点和上一个观察点相等的预测方法就叫朴素法
如果数据集在一段时间内都很稳定,我们想预测第二天的价格,可以取前面一天的价格,预测第二天的值。这种假设第一个预测点和上一个观察点相等的预测方法就叫朴素法

dd = np.asarray(train['Count'])
y_hat = test.copy()
y_hat['naive'] = dd[len(dd) - 1]
plt.figure(figsize=(12, 8))
plt.plot(train.index, train['Count'], label='Train')
plt.plot(test.index, test['Count'], label='Test')
plt.plot(y_hat.index, y_hat['naive'], label='Naive Forecast')
plt.legend(loc='best')
plt.title("Naive Forecast")
plt.show()
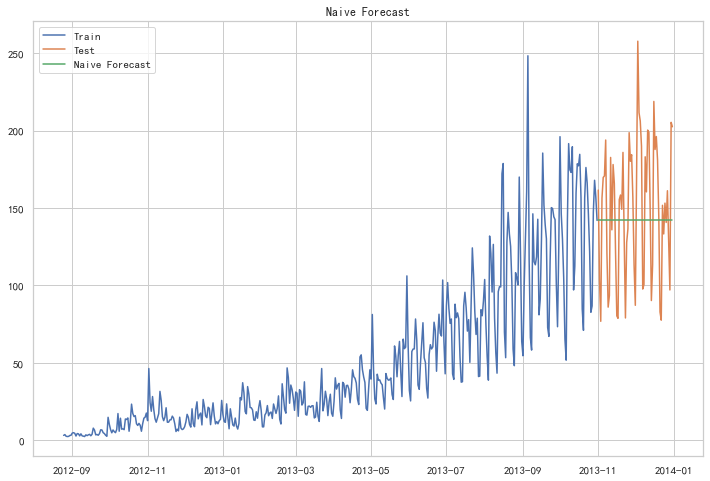
朴素法并不适合变化很大的数据集,最适合稳定性很高的数据集。我们计算下均方根误差,检查模型在测试数据集上的准确率:
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat['naive']))
print(rms)43.91640614391676
最终均方根误差RMS为:43.91640614391676
简单平均法
物品价格会随机上涨和下跌,平均价格会保持一致。我们经常会遇到一些数据集,虽然在一定时期内出现小幅变动,但每个时间段的平均值确实保持不变。这种情况下,我们可以预测出第二天的价格大致和过去天数的价格平均值一致。这种将预期值等同于之前所有观测点的平均值的预测方法就叫简单平均法

y_hat_avg = test.copy()
y_hat_avg['avg_forecast'] = train['Count'].mean()
plt.figure(figsize=(12,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['avg_forecast'], label='Average Forecast')
plt.legend(loc='best')
plt.show()
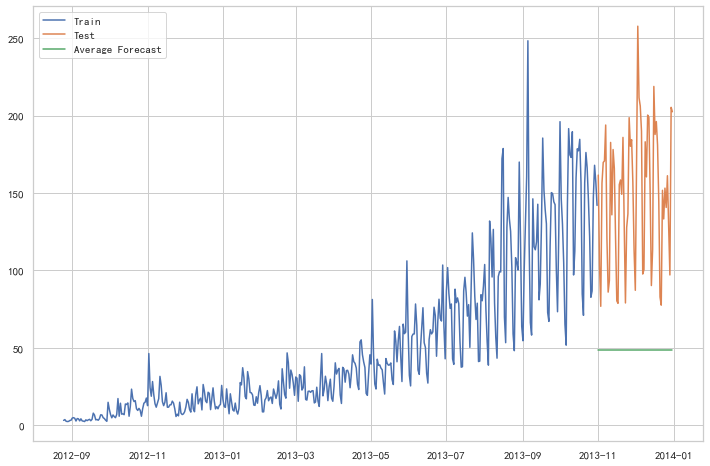
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['avg_forecast']))
print(rms)109.88526527082863
这种模型并没有改善准确率。因此我们可以从中推断出当每个时间段的平均值保持不变时,这种 方法的效果才能达到最好。虽然朴素法的准确率高于简单平均法,但这并不意味着朴素法在所有 的数据集上都比简单平均法好
移动平均法
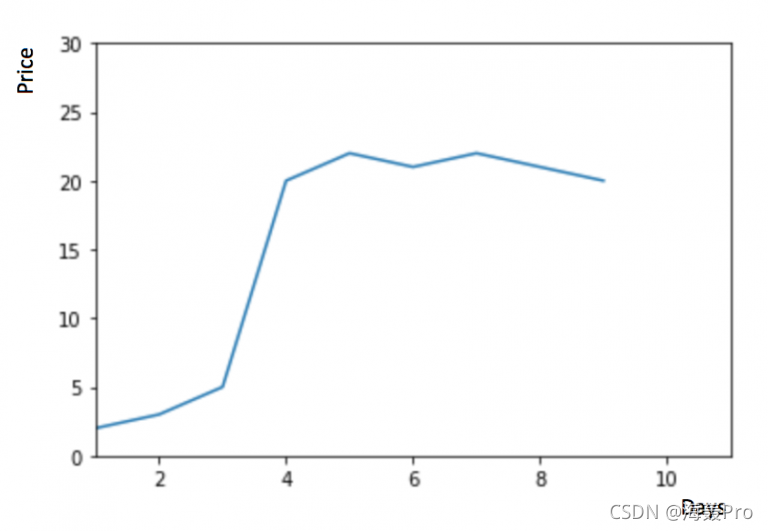 物品价格在一段时间内大幅上涨,但后来又趋于平稳。我们也经常会遇到这种数据集,比如价格或销售额某段时间大幅上升或下降。如果我们这时用之前的简单平均法,就得使用所有先前数据的平均值,但在这里使用之前的所有数据是说不通的,因为用开始阶段的价格值会大幅影响接下来日期的预测值。因此,我们只取最近几个时期的价格平均值。很明显这里的逻辑是只有最近的值最要紧。这种用某些窗口期计算平均值的预测方法就叫移动平均法。
物品价格在一段时间内大幅上涨,但后来又趋于平稳。我们也经常会遇到这种数据集,比如价格或销售额某段时间大幅上升或下降。如果我们这时用之前的简单平均法,就得使用所有先前数据的平均值,但在这里使用之前的所有数据是说不通的,因为用开始阶段的价格值会大幅影响接下来日期的预测值。因此,我们只取最近几个时期的价格平均值。很明显这里的逻辑是只有最近的值最要紧。这种用某些窗口期计算平均值的预测方法就叫移动平均法。
 移动平均法实际很有效,特别是当你为时序选择了正确的p值时
移动平均法实际很有效,特别是当你为时序选择了正确的p值时
y_hat_avg = test.copy()
y_hat_avg['moving_avg_forecast'] = train['Count'].rolling(60).mean().iloc[-1]
plt.figure(figsize=(16,8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['moving_avg_forecast'], label='Moving Average Forecast')
plt.legend(loc='best')
plt.show()
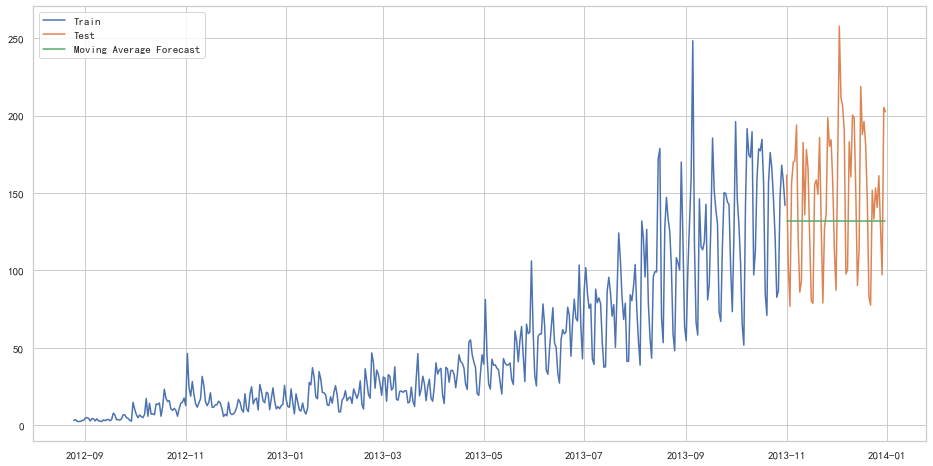
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['moving_avg_forecast']))
print(rms)46.72840725106963
我们可以看到,对于这个数据集,朴素法比简单平均法和移动平均法的表现要好。此外,我们还可以试试简单指数平滑法,它比移动平均法的一个进步之处就是相当于对移动平均法进行了加权。在上文移动平均法可以看到,我们对“p”中的观察值赋予了同样的权重。但是我们可能遇到一些情况,比如“p”中每个观察值会以不同的方式影响预测结果。将过去观察值赋予不同权重的方法就叫做加权移动平均法。加权移动平均法其实还是一种移动平均法,只是“滑动窗口期”内的值被赋予不同的权重,通常来讲,最近时间点的值发挥的作用更大了。
 这种方法并非选择一个窗口期的值,而是需要一列权重值(相加后为1)。例如,如果我们选择[0.40, 0.25, 0.20, 0.15]作为权值,我们会为最近的4个时间点分别赋给40%,25%,20%和15%的权重。
这种方法并非选择一个窗口期的值,而是需要一列权重值(相加后为1)。例如,如果我们选择[0.40, 0.25, 0.20, 0.15]作为权值,我们会为最近的4个时间点分别赋给40%,25%,20%和15%的权重。
简单指数平滑法
我们注意到简单平均法和加权移动平均法在选取时间点的思路上存在较大的差异。我们就需要在这两种方法之间取一个折中的方法,在将所有数据考虑在内的同时也能给数据赋予不同非权重。例如,相比更早时期内的观测值,它会给近期的观测值赋予更大的权重。按照这种原则工作的方法就叫做简单指数平滑法。它通过加权平均值计算出预测值,其中权重随着观测值从早期到晚期的变化呈指数级下降,最小的权重和最早的观测值相关:
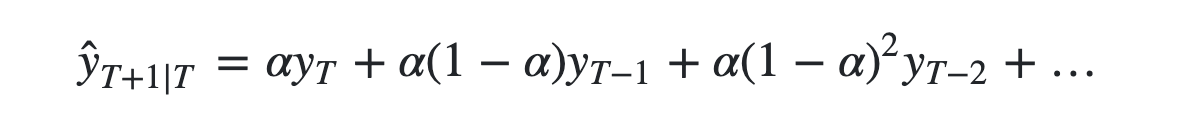

from statsmodels.tsa.api import SimpleExpSmoothing
y_hat_avg = test.copy()
fit = SimpleExpSmoothing(np.asarray(train['Count'])).fit(smoothing_level=0.6, optimized=False)
y_hat_avg['SES'] = fit.forecast(len(test))
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SES'], label='SES')
plt.legend(loc='best')
plt.show()
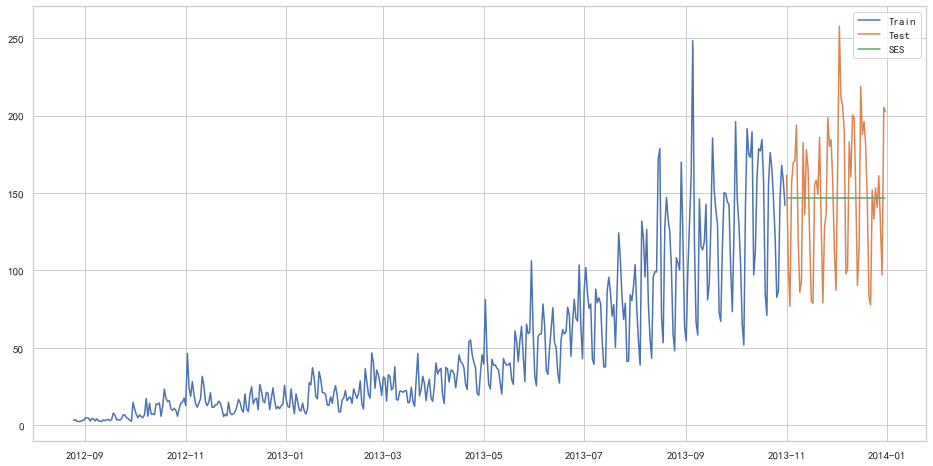
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['SES']))
print(rms)43.357625225228155
以上几种模型似乎效果都不太好hhh
霍尔特线性趋势法
如果物品的价格是不断上涨的,我们上面的方法并没有考虑这种趋势,即我们在一段时间内观察到的价格的总体模式。在上图例子中,我们可以看到物品的价格呈上涨趋势。虽然上面这些方法都可以应用于这种趋势,但我们仍需要一种方法可以在无需假设的情况下,准确预测出价格趋势。这种考虑到数据集变化趋势的方法就叫做霍尔特线性趋势法。
每个时序数据集可以分解为相应的几个部分:趋势(Trend),季节性(Seasonal)和残差(Residual)。任何呈现某种趋势的数据集都可以用霍尔特线性趋势法用于预测。
import statsmodels.api as sm
sm.tsa.seasonal_decompose(train['Count']).plot()
result = sm.tsa.stattools.adfuller(train['Count'])
plt.show()
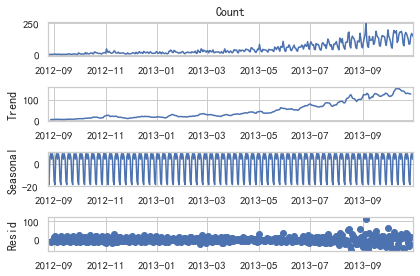
我们从图中可以看出,该数据集呈上升趋势。因此我们可以用霍尔特线性趋势法预测未来价格。该算法包含三个方程:一个水平方程,一个趋势方程,一个方程将二者相加以得到预测值y^
我们在上面算法中预测的值称为水平(level)。正如简单指数平滑一样,这里的水平方程显示它是观测值和样本内单步预测值的加权平均数,趋势方程显示它是根据 ℓ(t)−ℓ(t−1) 和之前的预测趋势 b(t−1) 在时间t处的预测趋势的加权平均值。
我们将这两个方程相加,得出一个预测函数。我们也可以将两者相乘而不是相加得到一个乘法预测方程。当趋势呈线性增加和下降时,我们用相加得到的方程;当趋势呈指数级增加或下降时,我们用相乘得到的方程。实践操作显示,用相乘得到的方程,预测结果会更稳定,但用相加得到的方程,更容易理解。
from statsmodels.tsa.api import Holt
y_hat_avg = test.copy()
fit = Holt(np.asarray(train['Count'])).fit(smoothing_level=0.3, smoothing_trend=0.1)
y_hat_avg['Holt_linear'] = fit.forecast(len(test))
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['Holt_linear'], label='Holt_linear')
plt.legend(loc='best')
plt.show()
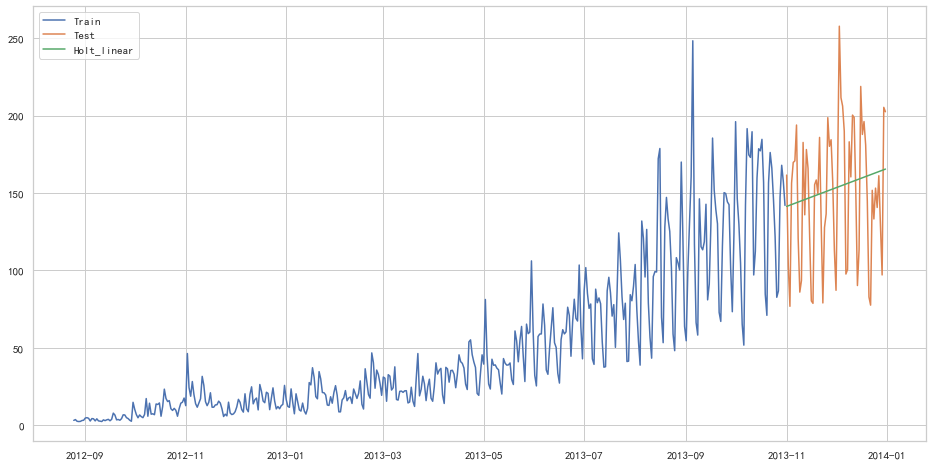
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['Holt_linear']))
print(rms)43.056259611507286
Holt-Winters季节性预测模型
在应用这种算法前,我们先介绍一个新术语。假如有家酒店坐落在半山腰上,夏季的时候生意很好,顾客很多,但每年其余时间顾客很少。因此,每年夏季的收入会远高于其它季节,而且每年都是这样,那么这种重复现象叫做“季节性”(Seasonality)。如果数据集在一定时间段内的固定区间内呈现相似的模式,那么该数据集就具有季节性
 我们之前讨论的5种模型在预测时并没有考虑到数据集的季节性,因此我们需要一种能考虑这种因素的方法。应用到这种情况下的算法就叫做Holt-Winters季节性预测模型,它是一种三次指数平滑预测,其背后的理念就是除了水平和趋势外,还将指数平滑应用到季节分量上。
我们之前讨论的5种模型在预测时并没有考虑到数据集的季节性,因此我们需要一种能考虑这种因素的方法。应用到这种情况下的算法就叫做Holt-Winters季节性预测模型,它是一种三次指数平滑预测,其背后的理念就是除了水平和趋势外,还将指数平滑应用到季节分量上。
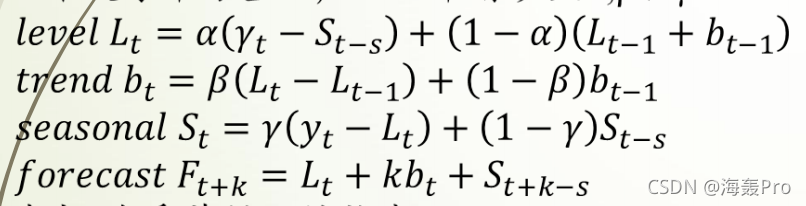 其中 s 为季节循环的长度,0≤α≤ 1, 0 ≤β≤ 1 , 0≤γ≤ 1。水平函数为季节性调整的观测值和时间点t处非季节预测之间的加权平均值。趋势函数和霍尔特线性方法中的含义相同。季节函数为当前季节指数和去年同一季节的季节性指数之间的加权平均值。
其中 s 为季节循环的长度,0≤α≤ 1, 0 ≤β≤ 1 , 0≤γ≤ 1。水平函数为季节性调整的观测值和时间点t处非季节预测之间的加权平均值。趋势函数和霍尔特线性方法中的含义相同。季节函数为当前季节指数和去年同一季节的季节性指数之间的加权平均值。
在本算法,我们同样可以用相加和相乘的方法。当季节性变化大致相同时,优先选择相加方法,而当季节变化的幅度与各时间段的水平成正比时,优先选择相乘的方法。
from statsmodels.tsa.api import ExponentialSmoothing
y_hat_avg = test.copy()
fit1 = ExponentialSmoothing(np.asarray(train['Count']), seasonal_periods=7, trend='add', seasonal='add', ).fit()
y_hat_avg['Holt_Winter'] = fit1.forecast(len(test))
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['Holt_Winter'], label='Holt_Winter')
plt.legend(loc='best')
plt.show()
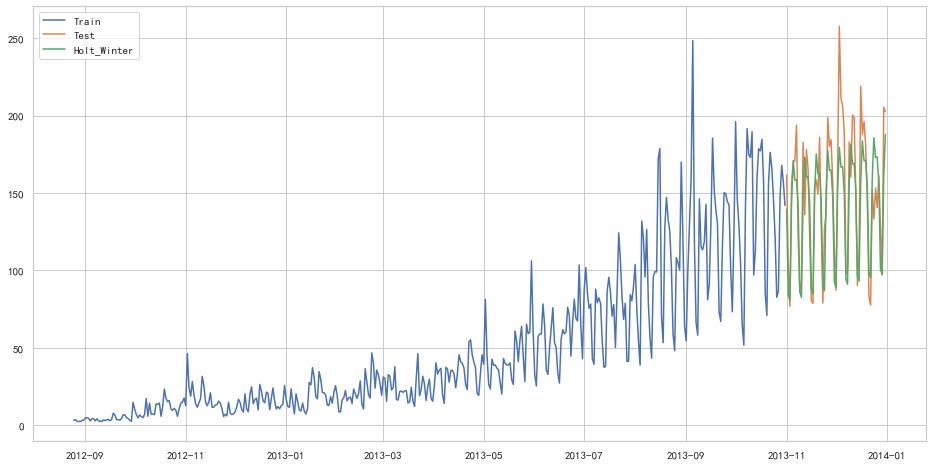
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['Holt_Winter']))
print(rms)25.26498570407121
自回归移动平均模型(ARIMA)
另一个场景的时序模型是自回归移动平均模型(ARIMA)。指数平滑模型都是基于数据中的趋势和季节性的描述,而自回归移动平均模型的目标是描述数据中彼此之间的关系。ARIMA的一个优化版就是季节性ARIMA。它像Holt-Winters季节性预测模型一样,也把数据集的季节性考虑在内。
import statsmodels.api as sm
y_hat_avg = test.copy()
fit1 = sm.tsa.statespace.SARIMAX(train.Count, order=(2, 1, 4), seasonal_order=(0, 1, 1, 7)).fit()
y_hat_avg['SARIMA'] = fit1.predict(start="2013-11-1", end="2013-12-31", dynamic=True)
plt.figure(figsize=(16, 8))
plt.plot(train['Count'], label='Train')
plt.plot(test['Count'], label='Test')
plt.plot(y_hat_avg['SARIMA'], label='SARIMA')
plt.legend(loc='best')
plt.show()D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\base\model.py:566: ConvergenceWarning: Maximum Likelihood optimization failed to converge. Check mle_retvals
warnings.warn("Maximum Likelihood optimization failed to "
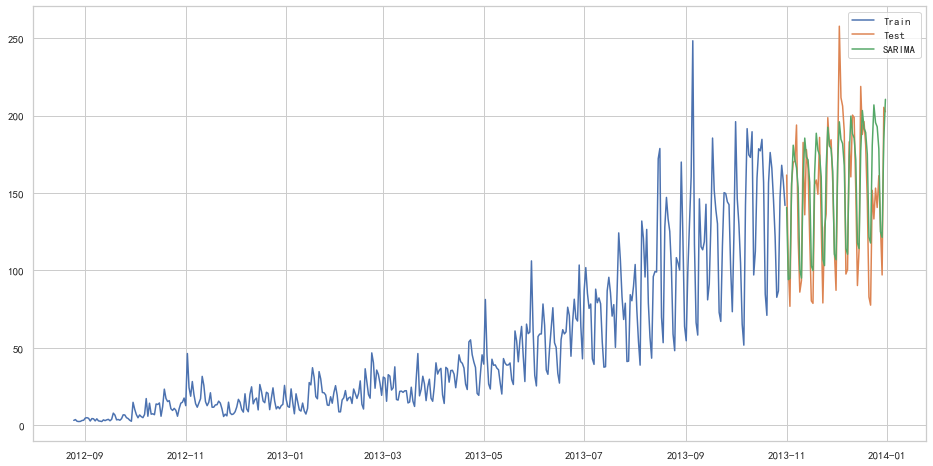
from sklearn.metrics import mean_squared_error
from math import sqrt
rms = sqrt(mean_squared_error(test['Count'], y_hat_avg['SARIMA']))
print(rms)26.043525937455975
随机序列
创建时间序列
date_range
- 可以指定开始时间与周期
- H:小时
- D:天
- M:月 从2016-07-01开始,周期为10,间隔为3天,生成的时间序列为下:
import pandas as pd
import numpy as np
from datetime import *
import time
rng = pd.date_range('2016-07-01', periods = 10, freq = '3D')
rngDatetimeIndex(['2016-07-01', '2016-07-04', '2016-07-07', '2016-07-10',
'2016-07-13', '2016-07-16', '2016-07-19', '2016-07-22',
'2016-07-25', '2016-07-28'],
dtype='datetime64[ns]', freq='3D')
在Series中,指定index,将时间作为索引,产生随机序列:
time=pd.Series(np.random.randn(20),
index=pd.date_range(date(2016,1,1),periods=20))
print(time)2016-01-01 0.097992
2016-01-02 -0.404909
2016-01-03 0.653857
2016-01-04 -0.002989
2016-01-05 0.364106
2016-01-06 -0.240264
2016-01-07 -1.215996
2016-01-08 1.241052
2016-01-09 0.837406
2016-01-10 -1.280999
2016-01-11 0.590210
2016-01-12 -1.563861
2016-01-13 0.177527
2016-01-14 -1.851483
2016-01-15 0.590123
2016-01-16 -1.381618
2016-01-17 2.185482
2016-01-18 -2.144004
2016-01-19 -1.218511
2016-01-20 -0.960300
Freq: D, dtype: float64
truncate过滤
过滤掉2016-1-10之前的数据:
time.truncate(before='2016-1-10')2016-01-10 -1.280999
2016-01-11 0.590210
2016-01-12 -1.563861
2016-01-13 0.177527
2016-01-14 -1.851483
2016-01-15 0.590123
2016-01-16 -1.381618
2016-01-17 2.185482
2016-01-18 -2.144004
2016-01-19 -1.218511
2016-01-20 -0.960300
Freq: D, dtype: float64
过滤掉2016-1-10之后的数据:
time.truncate(after='2016-1-10')2016-01-01 0.097992
2016-01-02 -0.404909
2016-01-03 0.653857
2016-01-04 -0.002989
2016-01-05 0.364106
2016-01-06 -0.240264
2016-01-07 -1.215996
2016-01-08 1.241052
2016-01-09 0.837406
2016-01-10 -1.280999
Freq: D, dtype: float64
通过时间索引,提取数据:
print(time['2016-01-15'])0.5901226225267066
指定起始时间和终止时间,产生时间序列:
data=pd.date_range('2010-01-01','2011-01-01',freq='M')
print(data)DatetimeIndex(['2010-01-31', '2010-02-28', '2010-03-31', '2010-04-30',
'2010-05-31', '2010-06-30', '2010-07-31', '2010-08-31',
'2010-09-30', '2010-10-31', '2010-11-30', '2010-12-31'],
dtype='datetime64[ns]', freq='M')
时间戳
pd.Timestamp('2016-07-10')Timestamp('2016-07-10 00:00:00')
可以指定更多细节
pd.Timestamp('2016-07-10 10')Timestamp('2016-07-10 10:00:00')
pd.Timestamp('2016-07-10 10:15')Timestamp('2016-07-10 10:15:00')
t = pd.Timestamp('2016-07-10 10:15:19')
tTimestamp('2016-07-10 10:15:19')
时间区间
pd.Period('2016-01')Period('2016-01', 'M')
pd.Period('2016-01-01')Period('2016-01-01', 'D')
时间加减
TIME OFFSETS
产生一个一天的时间偏移量:
pd.Timedelta('1 day')Timedelta('1 days 00:00:00')
得到2016-01-01 10:10的后一天时刻:
pd.Period('2016-01-01 10:10') + pd.Timedelta('1 day')Period('2016-01-02 10:10', 'T')
时间戳加减
pd.Timestamp('2016-01-01 10:10') + pd.Timedelta('1 day')Timestamp('2016-01-02 10:10:00')
加15 ns:
pd.Timestamp('2016-01-01 10:10') + pd.Timedelta('15 ns')Timestamp('2016-01-01 10:10:00.000000015')
在时间间隔刹参数中,我们既可以写成25H,也可以写成1D1H这种通俗的表达:
p1 = pd.period_range('2016-01-01 10:10', freq = '25H', periods = 10)
p2 = pd.period_range('2016-01-01 10:10', freq = '1D1H', periods = 10)p1PeriodIndex(['2016-01-01 10:00', '2016-01-02 11:00', '2016-01-03 12:00',
'2016-01-04 13:00', '2016-01-05 14:00', '2016-01-06 15:00',
'2016-01-07 16:00', '2016-01-08 17:00', '2016-01-09 18:00',
'2016-01-10 19:00'],
dtype='period[25H]', freq='25H')
p2PeriodIndex(['2016-01-01 10:00', '2016-01-02 11:00', '2016-01-03 12:00',
'2016-01-04 13:00', '2016-01-05 14:00', '2016-01-06 15:00',
'2016-01-07 16:00', '2016-01-08 17:00', '2016-01-09 18:00',
'2016-01-10 19:00'],
dtype='period[25H]', freq='25H')
指定索引
rng = pd.date_range('2016 Jul 1', periods = 10, freq = 'D')
rng
pd.Series(range(len(rng)), index = rng)2016-07-01 0
2016-07-02 1
2016-07-03 2
2016-07-04 3
2016-07-05 4
2016-07-06 5
2016-07-07 6
2016-07-08 7
2016-07-09 8
2016-07-10 9
Freq: D, dtype: int64
构造任意的Series结构时间序列数据:
periods = [pd.Period('2016-01'), pd.Period('2016-02'), pd.Period('2016-03')]
ts = pd.Series(np.random.randn(len(periods)), index = periods)
ts2016-01 -0.044480
2016-02 0.816341
2016-03 -0.875320
Freq: M, dtype: float64
type(ts.index)pandas.core.indexes.period.PeriodIndex
时间戳和时间周期可以转换
ts = pd.Series(range(10), pd.date_range('07-10-16 8:00', periods = 10, freq = 'H'))
ts2016-07-10 08:00:00 0
2016-07-10 09:00:00 1
2016-07-10 10:00:00 2
2016-07-10 11:00:00 3
2016-07-10 12:00:00 4
2016-07-10 13:00:00 5
2016-07-10 14:00:00 6
2016-07-10 15:00:00 7
2016-07-10 16:00:00 8
2016-07-10 17:00:00 9
Freq: H, dtype: int64
将时间周期转化为时间戳:
ts_period = ts.to_period()
ts_period2016-07-10 08:00 0
2016-07-10 09:00 1
2016-07-10 10:00 2
2016-07-10 11:00 3
2016-07-10 12:00 4
2016-07-10 13:00 5
2016-07-10 14:00 6
2016-07-10 15:00 7
2016-07-10 16:00 8
2016-07-10 17:00 9
Freq: H, dtype: int64
时间周期和时间戳区别:
对时间周期的切片操作:
ts_period['2016-07-10 08:30':'2016-07-10 11:45'] 2016-07-10 08:00 0
2016-07-10 09:00 1
2016-07-10 10:00 2
2016-07-10 11:00 3
Freq: H, dtype: int64
对时间戳的切片操作结果:
ts['2016-07-10 08:30':'2016-07-10 11:45'] 2016-07-10 09:00:00 1
2016-07-10 10:00:00 2
2016-07-10 11:00:00 3
Freq: H, dtype: int64
数据重采样
- 时间数据由一个频率转换到另一个频率
- 降采样:例如将365天数据变为12个月数据
- 升采样:相反
从1/1/2011开始,时间间隔为1天,产生90个时间数据:
import pandas as pd
import numpy as np
rng = pd.date_range('1/1/2011', periods=90, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts.head()
2011-01-01 1.160658
2011-01-02 0.691987
2011-01-03 0.204438
2011-01-04 -1.703135
2011-01-05 1.090152
Freq: D, dtype: float64
降采样
将以上数据降采样为月数据,观察每个月数据之和:
ts.resample('M').sum()2011-01-31 3.166377
2011-02-28 2.807078
2011-03-31 -3.865396
Freq: M, dtype: float64
降采样为3天,并求和:
ts.resample('3D').sum()2011-01-01 2.057084
2011-01-04 1.154984
2011-01-07 2.868148
2011-01-10 -0.244841
2011-01-13 -0.279276
2011-01-16 0.669061
2011-01-19 0.004282
2011-01-22 -1.647027
2011-01-25 -0.652588
2011-01-28 -0.387634
2011-01-31 0.009486
2011-02-03 0.168137
2011-02-06 0.849931
2011-02-09 -1.459601
2011-02-12 -0.636281
2011-02-15 -0.003550
2011-02-18 -0.869950
2011-02-21 1.558289
2011-02-24 0.864958
2011-02-27 2.460489
2011-03-02 -0.384647
2011-03-05 1.383810
2011-03-08 0.458777
2011-03-11 -2.690309
2011-03-14 0.693394
2011-03-17 0.821281
2011-03-20 -1.328988
2011-03-23 -0.177204
2011-03-26 -1.358276
2011-03-29 -1.793880
Freq: 3D, dtype: float64
计算降采样后数据均值:
day3Ts = ts.resample('3D').mean()
day3Ts2011-01-01 0.685695
2011-01-04 0.384995
2011-01-07 0.956049
2011-01-10 -0.081614
2011-01-13 -0.093092
2011-01-16 0.223020
2011-01-19 0.001427
2011-01-22 -0.549009
2011-01-25 -0.217529
2011-01-28 -0.129211
2011-01-31 0.003162
2011-02-03 0.056046
2011-02-06 0.283310
2011-02-09 -0.486534
2011-02-12 -0.212094
2011-02-15 -0.001183
2011-02-18 -0.289983
2011-02-21 0.519430
2011-02-24 0.288319
2011-02-27 0.820163
2011-03-02 -0.128216
2011-03-05 0.461270
2011-03-08 0.152926
2011-03-11 -0.896770
2011-03-14 0.231131
2011-03-17 0.273760
2011-03-20 -0.442996
2011-03-23 -0.059068
2011-03-26 -0.452759
2011-03-29 -0.597960
Freq: 3D, dtype: float64
升采样
直接升采样是有问题的,因为有数据缺失:
print(day3Ts.resample('D').asfreq())2011-01-01 0.685695
2011-01-02 NaN
2011-01-03 NaN
2011-01-04 0.384995
2011-01-05 NaN
...
2011-03-25 NaN
2011-03-26 -0.452759
2011-03-27 NaN
2011-03-28 NaN
2011-03-29 -0.597960
Freq: D, Length: 88, dtype: float64
需要进行插值
插值方法
- ffill 空值取前面的值
- bfill 空值取后面的值
- interpolate 线性取值
使用ffill插值:
day3Ts.resample('D').ffill(1)2011-01-01 0.685695
2011-01-02 0.685695
2011-01-03 NaN
2011-01-04 0.384995
2011-01-05 0.384995
...
2011-03-25 NaN
2011-03-26 -0.452759
2011-03-27 -0.452759
2011-03-28 NaN
2011-03-29 -0.597960
Freq: D, Length: 88, dtype: float64
使用bfill插值:
day3Ts.resample('D').bfill(1)2011-01-01 0.685695
2011-01-02 NaN
2011-01-03 0.384995
2011-01-04 0.384995
2011-01-05 NaN
...
2011-03-25 -0.452759
2011-03-26 -0.452759
2011-03-27 NaN
2011-03-28 -0.597960
2011-03-29 -0.597960
Freq: D, Length: 88, dtype: float64
使用interpolate线性取值:
day3Ts.resample('D').interpolate('linear')2011-01-01 0.685695
2011-01-02 0.585461
2011-01-03 0.485228
2011-01-04 0.384995
2011-01-05 0.575346
...
2011-03-25 -0.321528
2011-03-26 -0.452759
2011-03-27 -0.501159
2011-03-28 -0.549560
2011-03-29 -0.597960
Freq: D, Length: 88, dtype: float64
Pandas滑动窗口
为了提升数据的准确性,将某个点的取值扩大到包含这个点的一段区间,用区间来进行判断,这个区间就是窗口。例如想使用2011年1月1日的一个数据,单取这个时间点的数据当然是可行的,但是太过绝对,有没有更好的办法呢?可以选取2010年12月16日到2011年1月15日,通过求均值来评估1月1日这个点的值,2010-12-16到2011-1-15就是一个窗口,窗口的长度window=30.
移动窗口就是窗口向一端滑行,默认是从右往左,每次滑行并不是区间整块的滑行,而是一个单位一个单位的滑行。例如窗口2010-12-16到2011-1-15,下一个窗口并不是2011-1-15到2011-2-15,而是2010-12-17到2011-1-16(假设数据的截取是以天为单位),整体向右移动一个单位,而不是一个窗口。这样统计的每个值始终都是30单位的均值。
也就是我们在统计学中的移动平均法。
%matplotlib inline
import matplotlib.pylab
import numpy as np
import pandas as pd指定600个数据的序列:
df = pd.Series(np.random.randn(600), index = pd.date_range('7/1/2016', freq = 'D', periods = 600))df.head()2016-07-01 -0.107912
2016-07-02 -0.751786
2016-07-03 -1.188762
2016-07-04 -1.889090
2016-07-05 0.054006
Freq: D, dtype: float64
指定该序列一个单位长度为10的滑块
r = df.rolling(window = 10)
rRolling [window=10,center=False,axis=0]
输出滑块内的平均值,窗口中的值从覆盖整个窗口的位置开始产生,在此之前即为NaN,举例如下:窗口大小为10,前9个都不足够为一个一个窗口的长度,因此都无法取值
#r.max, r.median, r.std, r.skew, r.sum, r.var
print(r.mean())2016-07-01 NaN
2016-07-02 NaN
2016-07-03 NaN
2016-07-04 NaN
2016-07-05 NaN
...
2018-02-16 0.042507
2018-02-17 -0.016247
2018-02-18 -0.126695
2018-02-19 -0.102721
2018-02-20 -0.283708
Freq: D, Length: 600, dtype: float64
通过画图库来看原始序列与滑动窗口产生序列的关系图,原始数据用红色表示,移动平均后数据用蓝色点表示:
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(15, 5))
df.plot(style='r--')
df.rolling(window=10).mean().plot(style='b')<matplotlib.axes._subplots.AxesSubplot at 0x242d88e86d0>
可以看到,原始值浮动差异较大,而移动平均后数值较为平稳
数据平稳性与差分法
平稳性:
平稳性就是要求经由样本时间序列所得到的拟合曲线在未来的一段期间内仍能顺着现有的形态“惯性”地延续下去 平稳性要求序列的均值和方差不发生明显变化 严平稳与弱平稳:
严平稳:严平稳表示的分布不随时间的改变而改变。 如:白噪声(正态),无论怎么取,都是期望为0,方差为1 弱平稳:期望与相关系数(依赖性)不变 未来某时刻的t的值Xt就要依赖于它的过去信息,所以需要依赖性
差分法:时间序列在t与t-1时刻的差值:
%load_ext autoreload
%autoreload 2
%matplotlib inline
%config InlineBackend.figure_format='retina'
from __future__ import absolute_import, division, print_function
# http://www.lfd.uci.edu/~gohlke/pythonlibs/#xgboost
import sys
import os
import pandas as pd
import numpy as np
# # Remote Data Access
# import pandas_datareader.data as web
# import datetime
# # reference: https://pandas-datareader.readthedocs.io/en/latest/remote_data.html
# TSA from Statsmodels
import statsmodels.api as sm
import statsmodels.formula.api as smf
import statsmodels.tsa.api as smt
# Display and Plotting
import matplotlib.pylab as plt
import seaborn as sns
pd.set_option('display.float_format', lambda x: '%.5f' % x) # pandas
np.set_printoptions(precision=5, suppress=True) # numpy
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 100)
# seaborn plotting style
sns.set(style='ticks', context='poster')
读取数据
Sentiment = 'data/sentiment.csv'
data = pd.read_csv(Sentiment, index_col=0, parse_dates=[0])
data| UMCSENT | |
|---|---|
| DATE | |
| 2000-01-01 | 112.00000 |
| 2000-02-01 | 111.30000 |
| 2000-03-01 | 107.10000 |
| 2000-04-01 | 109.20000 |
| 2000-05-01 | 110.70000 |
| ... | ... |
| 2016-03-01 | 91.00000 |
| 2016-04-01 | 89.00000 |
| 2016-05-01 | 94.70000 |
| 2016-06-01 | 93.50000 |
| 2016-07-01 | 90.00000 |
199 rows × 1 columns
选择2001-2015的部分,画图
sentiment_short = data.loc['2001':'2015']
#一阶差分
sentiment_short.loc[:,'diff_1'] = sentiment_short.loc[:,'UMCSENT'].diff(1)
#二阶差分
sentiment_short.loc[:,'diff_2'] = sentiment_short.loc[:,'diff_1'].diff(1)
print(sentiment_short.head())
sentiment_short.plot(subplots=True, figsize=(18, 12))
UMCSENT diff_1 diff_2
DATE
2001-01-01 94.70000 NaN NaN
2001-02-01 90.60000 -4.10000 NaN
2001-03-01 91.50000 0.90000 5.00000
2001-04-01 88.40000 -3.10000 -4.00000
2001-05-01 92.00000 3.60000 6.70000
array([<matplotlib.axes._subplots.AxesSubplot object at 0x00000242D86F0A90>,
<matplotlib.axes._subplots.AxesSubplot object at 0x00000242D83458B0>,
<matplotlib.axes._subplots.AxesSubplot object at 0x00000242D8521D00>],
dtype=object)
ARIMA模型
AR模型
自回归模型(AR)
- 描述当前值与历史值之间的关系,用变量自身的历史时间数据对自身进行预测
- 自回归模型必须满足平稳性的要求
- p阶自回归过程的公式定义:
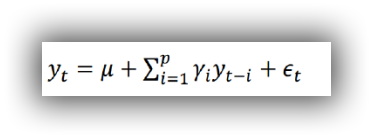
是当前值 是常数项 P 是阶数 是自相关系数 是误差
自回归模型的限制:
- 自回归模型是用自身的数据来进行预测
- 必须具有平稳性
- 必须具有自相关性,如果自相关系数(φi)小于0.5,则不宜采用
- 自回归只适用于预测与自身前期相关的现象
MA模型
移动平均模型(MA)
-
移动平均模型关注的是自回归模型中的误差项的累加
-
q阶自回归过程的公式定义:
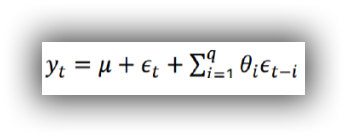
-
移动平均法能有效地消除预测中的随机波动
ARMA模型
自回归移动平均模型(ARMA)
自回归与移动平均的结合
公式定义:
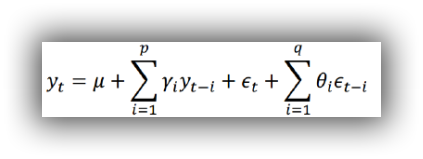
5.4 ARIMA模型 ARIMA(p,d,q)模型全称为差分自回归移动平均模型 (Autoregressive Integrated Moving Average Model,简记ARIMA)
- AR是自回归, p为自回归项; MA为移动平均q为移动平均项数,d为时间序列成为平稳时所做的差分次数,一般做一阶差分就够了,很少有做二阶差分的
- 原理:将非平稳时间序列转化为平稳时间序列然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型
相关函数评估(选择p、q值)方法
自相关函数ACF(autocorrelation function)
-
有序的随机变量序列与其自身相比较自相关函数反映了同一序列在不同时序的取值之间的相关性
-
公式:
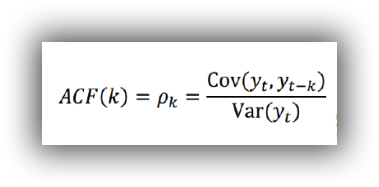
-
Pk的取值范围为[-1,1]
偏自相关函数(PACF)(partial autocorrelation function)
-
对于一个平稳AR§模型,求出滞后k自相关系数p(k)时实际上得到并不是x(t)与x(t-k)之间单纯的相关关系
-
x(t)同时还会受到中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的影响而这k-1个随机变量又都和x(t-k)具有相关关系,所以自相关系数p(k)里实际掺杂了其他变量对x(t)与x(t-k)的影响
-
剔除了中间k-1个随机变量x(t-1)、x(t-2)、……、x(t-k+1)的干扰之后x(t-k)对x(t)影响的相关程度。
-
ACF还包含了其他变量的影响而偏自相关系数PACF是严格这两个变量之间的相关性
ARIMA(p,d,q)阶数确定:

- 截尾:落在置信区间内(95%的点都符合该规则) ARIMA(p,d,q)阶数确定:
- AR§ 看PACF
- MA(q) 看ACF
利用AIC与BIC准则: 选择参数p、q
赤池信息准则(Akaike Information Criterion,AIC)
AIC是衡量统计模型拟合优良性的一种标准,由日本统计学家赤池弘次在1974年提出,它建立在熵的概念上,提供了权衡估计模型复杂度和拟合数据优良性的标准。
-
通常情况下,AIC定义为:

-
其中k是模型参数个数,L是似然函数。从一组可供选择的模型中选择最佳模型时,通常选择AIC最小的模型。
-
当两个模型之间存在较大差异时,差异主要体现在似然函数项,当似然函数差异不显著时,上式第一项,即模型复杂度则起作用,从而参数个数少的模型是较好的选择。
-
一般而言,当模型复杂度提高(k增大)时,似然函数L也会增大,从而使AIC变小,但是k过大时,似然函数增速减缓,导致AIC增大,模型过于复杂容易造成过拟合现象。
-
目标是选取AIC最小的模型,AIC不仅要提高模型拟合度(极大似然),而且引入了惩罚项,使模型参数尽可能少,有助于降低过拟合的可能性。
贝叶斯信息准则(Bayesian Information Criterion,BIC)
BIC(Bayesian InformationCriterion)贝叶斯信息准则与AIC相似,用于模型选择,1978年由Schwarz提出。训练模型时,增加参数数量,也就是增加模型复杂度,会增大似然函数,但是也会导致过拟合现象,针对该问题,AIC和BIC均引入了与模型参数个数相关的惩罚项,BIC的惩罚项比AIC的大,考虑了样本数量,样本数量过多时,可有效防止模型精度过高造成的模型复杂度过高。

- 其中,k为模型参数个数,n为样本数量,L为似然函数。kln(n)惩罚项在维数过大且训练样本数据相对较少的情况下,可以有效避免出现维度灾难现象。
AIC与BIC比较
AIC和BIC的公式中前半部分是一样的,后半部分是惩罚项,当n≥8n≥8时,kln(n)≥2kkln(n)≥2k,所以,BIC相比AIC在大数据量时对模型参数惩罚得更多,导致BIC更倾向于选择参数少的简单模型。
模型残差检验:
- ARIMA模型的残差是否是平均值为0且方差为常数的正态分布
- QQ图:线性即正态分布
ARIMA建模流程:
- 将序列平稳(差分法确定d)
- p和q阶数确定:ACF与PACF
- ARIMA(p,d,q)
实战分析
sentiment的ARIMA模型
del sentiment_short['diff_2']
del sentiment_short['diff_1']
sentiment_short.head()| UMCSENT | |
|---|---|
| DATE | |
| 2001-01-01 | 94.70000 |
| 2001-02-01 | 90.60000 |
| 2001-03-01 | 91.50000 |
| 2001-04-01 | 88.40000 |
| 2001-05-01 | 92.00000 |
绘制ACF图、PACF图确定p、q值,其中阴影部分代表p、q的置信区间:
fig = plt.figure(figsize=(12,8))
#画ACF
ax1 = fig.add_subplot(211)
fig = sm.graphics.tsa.plot_acf(sentiment_short, lags=20,ax=ax1)#lags表示滞后的阶数
ax1.xaxis.set_ticks_position('bottom')
fig.tight_layout();
#画PACF
ax2 = fig.add_subplot(212)
fig = sm.graphics.tsa.plot_pacf(sentiment_short, lags=20, ax=ax2)
ax2.xaxis.set_ticks_position('bottom')
fig.tight_layout();
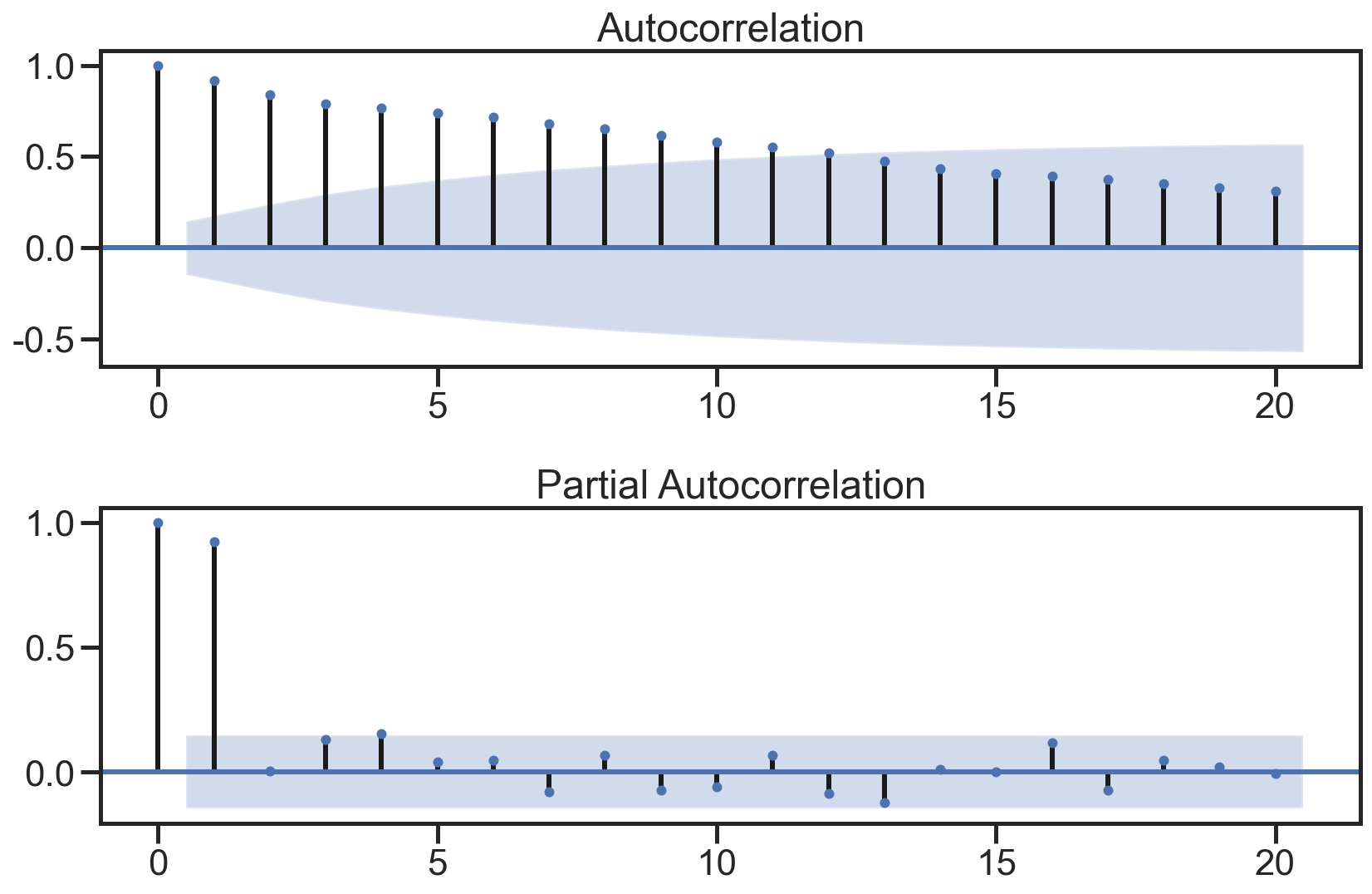
使用散点图绘制原始数据和k阶差分数据之间的关系,并求出相关系数:
lags=9
ncols=3
nrows=int(np.ceil(lags/ncols))
fig, axes = plt.subplots(ncols=ncols, nrows=nrows, figsize=(4*ncols, 4*nrows))
for ax, lag in zip(axes.flat, np.arange(1,lags+1, 1)):
lag_str = 't-{}'.format(lag)
X = (pd.concat([sentiment_short, sentiment_short.shift(-lag)], axis=1,
keys=['y'] + [lag_str]).dropna())
X.plot(ax=ax, kind='scatter', y='y', x=lag_str);
corr = X.corr().values[0][1] # as_matrix()是老版本的写法
ax.set_ylabel('Original')
ax.set_title('Lag: {} (corr={:.2f})'.format(lag_str, corr));
ax.set_aspect('equal');
sns.despine();
fig.tight_layout();
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
*c* argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with *x* & *y*. Please use the *color* keyword-argument or provide a 2-D array with a single row if you intend to specify the same RGB or RGBA value for all points.
在下图,分别绘制原始数据的残差图、直方图、ACF图和PACF图:
def tsplot(y, lags=None, title='', figsize=(14, 8)):
fig = plt.figure(figsize=figsize)
layout = (2, 2)
ts_ax = plt.subplot2grid(layout, (0, 0))
hist_ax = plt.subplot2grid(layout, (0, 1))
acf_ax = plt.subplot2grid(layout, (1, 0))
pacf_ax = plt.subplot2grid(layout, (1, 1))
y.plot(ax=ts_ax)
ts_ax.set_title(title)
y.plot(ax=hist_ax, kind='hist', bins=25)
hist_ax.set_title('Histogram')
smt.graphics.plot_acf(y, lags=lags, ax=acf_ax)
smt.graphics.plot_pacf(y, lags=lags, ax=pacf_ax)
[ax.set_xlim(0) for ax in [acf_ax, pacf_ax]]
sns.despine()
plt.tight_layout()
return ts_ax, acf_ax, pacf_ax
tsplot(sentiment_short, title='A Given Training Series', lags=20);
建立模型+参数选择(AIC、BIC):p范围[0 ,4],q范围[0, 4] d=0,遍历求最佳组合
arima200 = sm.tsa.SARIMAX(sentiment_short, order=(2,0,0))
model_results = arima200.fit()
#遍历,寻找适宜的参数
import itertools
p_min = 0
d_min = 0
q_min = 0
p_max = 4
d_max = 0
q_max = 4
# Initialize a DataFrame to store the results,,以BIC准则
results_bic = pd.DataFrame(index=['AR{}'.format(i) for i in range(p_min,p_max+1)],
columns=['MA{}'.format(i) for i in range(q_min,q_max+1)])
for p,d,q in itertools.product(range(p_min,p_max+1),
range(d_min,d_max+1),
range(q_min,q_max+1)):
if p==0 and d==0 and q==0:
results_bic.loc['AR{}'.format(p), 'MA{}'.format(q)] = np.nan
continue
try:
model = sm.tsa.ARIMA(sentiment_short, order=(p, d, q),
#enforce_stationarity=False,
#enforce_invertibility=False,
)
results = model.fit()
results_bic.loc['AR{}'.format(p), 'MA{}'.format(q)] = results.bic
except:
continue
results_bic = results_bic[results_bic.columns].astype(float) D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
D:\ProgramData\Anaconda3\lib\site-packages\statsmodels\tsa\base\tsa_model.py:524: ValueWarning: No frequency information was provided, so inferred frequency MS will be used.
warnings.warn('No frequency information was'
画出BIC值热度图
fig, ax = plt.subplots(figsize=(10, 8))
ax = sns.heatmap(results_bic,
mask=results_bic.isnull(),
ax=ax,
annot=True,
fmt='.2f',
)
ax.set_title('BIC')
plt.show()
模型评估:残差分析 正态分布 QQ图线性
model_results.plot_diagnostics(figsize=(16, 12))