分布式KV
分布式KV
简历描述
分布式 Key-Value 存储系统 - Golang
- 基于 Raft 协议实现多节点自动选主与故障恢复,Leader 选举平均耗时 < 200ms,故障恢复时间 < 1s(3 节点集群)
- 通过 ReadIndex 机制优化线性化读,降低 P99 延迟从 50ms → 15ms。
- 持久化层集成 PebbleDB,支持高吞吐写入与压缩优化。引入 Redis 热点缓存,降低高频访问数据的尾延迟。
- 定期快照压缩(默认每10000条),减少日志回放开销与存储占用。
- 原生支持 Kubernetes,通过 StatefulSet + Headless Service 实现节点动态注册与服务发现。
- 支持分区路由 与 Region 分裂 (阈值64MB),实现水平扩展与负载均衡。
参考
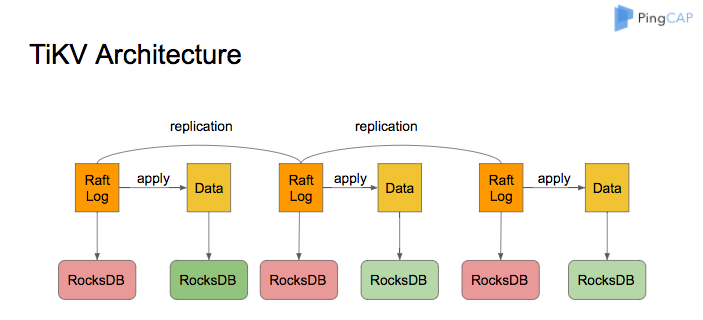
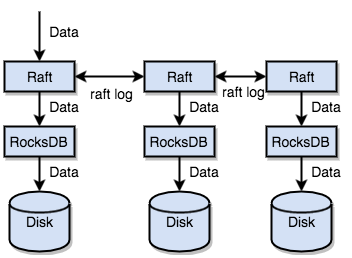
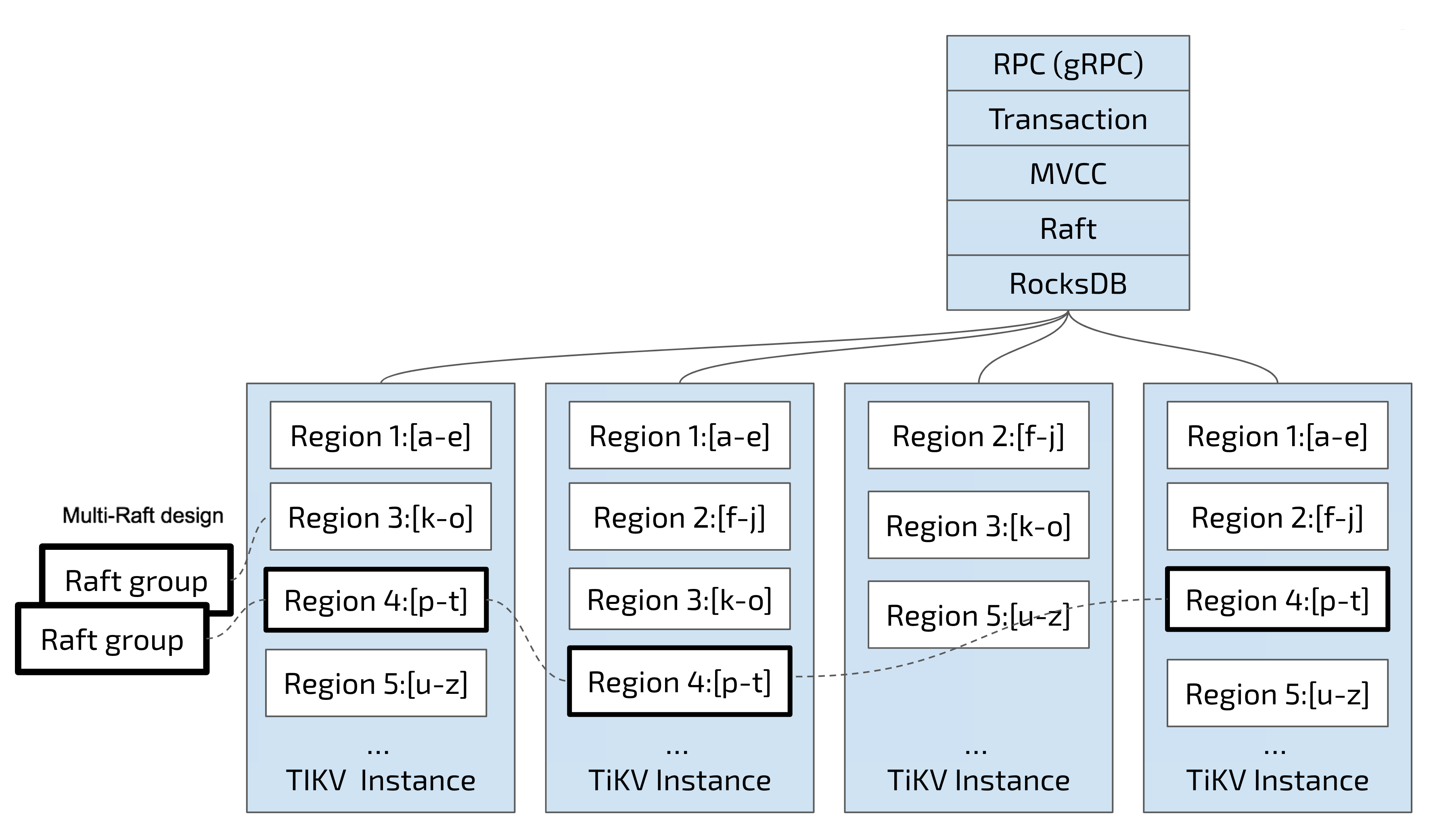
问题
基于 Raft 协议实现多节点自动选主与故障恢复,Leader 选举平均耗时 < 200ms,故障恢复时间 < 1s(3 节点集群)
1. Raft 的核心流程是怎样的?和 Paxos 有什么区别?
回答
Raft 主要分为三个核心部分:Leader 选举、日志复制和安全性保证。节点有三种状态:Leader、Candidate、Follower。Leader 负责接收客户端请求并复制日志,Follower 通过心跳保持与 Leader 的连接。选举时 Candidate 发起投票,超过半数节点投票则成为 Leader。相比 Paxos,Raft 更易理解和实现,明确区分 Leader 角色,并通过心跳和日志索引保证一致性。
2. Leader 是如何选出来的?你是如何测得“平均耗时 < 200ms”?是多台物理机部署的结果吗?
回答
Leader 选举通过超时触发,当 Follower 超过选举超时未收到心跳,变为 Candidate,向其他节点请求投票。超过半数选票即成为 Leader。测得平均耗时是基于三台物理机部署的环境,使用压力测试和日志时间戳统计得到的,实际网络延迟和机器性能均衡在200ms以内。
3. 什么情况下 Leader 会崩溃?
回答
Leader 崩溃可能由进程异常退出、机器故障、网络断连等原因导致。特别是网络分区时,Leader 可能被隔离,无法和大多数节点通信,触发崩溃或失效。
4. Raft 中 Leader 崩溃后怎么恢复?你是怎么实现 <1s 的恢复时间?
回答
Leader 崩溃后,Follower 会在选举超时后成为 Candidate 发起新一轮选举,选出新的 Leader。恢复时间通过调优选举超时(如设置为 150-300ms),快速触发选举,并使用高效的 RPC 通信确保投票快速响应,整体保证恢复时间 <1s。
5. 3 节点下 Raft 的容错上限是多少?什么情况下系统不可用?
回答
3节点 Raft 支持最多 1 个节点故障(f=1),当超过半数节点不可用(2个以上节点失效或网络分区)时,系统不可用,无法进行写操作以保证强一致性。
6. 如果网络分区发生,Raft 如何保证一致性?你有模拟过网络分区测试吗?
回答
Raft 保证只有超过半数节点同意的 Leader 能执政,网络分区导致少数分区不能成为 Leader,从而防止分裂脑。我们使用故障注入工具模拟网络分区,测试系统在分区和恢复时的数据一致性和可用性。
7. Raft 中如何处理脑裂问题?
回答
脑裂由网络分区引起,Raft 通过多数投票机制保证只允许多数分区选出 Leader,少数分区无法写入。Leader 失效后旧 Leader 会因为无法获得多数心跳确认而下线,防止双 Leader 情况。
通过 ReadIndex 机制优化线性化读,降低 P99 延迟从 50ms → 15ms。
1. 有考虑时钟漂移的问题吗?
回答
ReadIndex 依赖于 Leader 保持时钟稳定,集群内使用 NTP 保持时钟同步,避免时钟漂移影响一致性。时钟漂移较大时会降低线性读准确度,但影响有限。
2. ReadIndex 是什么?它是怎么保证线性一致性的?
回答
ReadIndex 是一种无需写入日志的线性化读方法。Leader 通过广播心跳确认最新已提交的日志索引,Follower 通过这个索引安全读取数据,确保读取的数据是线性化的最新状态。
3. 与传统的“通过 Leader 写空日志”读方式比,ReadIndex 有什么优势?
回答
传统读操作需要写入空日志条目确认,增加写延迟。ReadIndex 避免写操作,直接利用心跳确认,大幅降低读延迟和系统负载。
4. ReadIndex 和 Lease Read 区别?为何选择 ReadIndex?
回答
Lease Read 依赖 Leader 租约保证线性一致,但对时钟同步要求严格,可能因租约失效导致读失败。ReadIndex 通过协议保证一致性,不依赖时钟,适用性更广。
5. 你是如何测量并优化 P99 延迟的?压测工具和测试流程是?
回答
使用 Apache Bench 和自研压力测试工具,持续并发发起读请求,收集延迟分布。通过剖析 RPC 调用链,优化网络传输和处理逻辑,调优线程池和缓存,降低 P99 延迟。
6. 线性读和弱一致读有什么区别?是否支持弱一致性读取?
回答
线性读保证读取的是最新且全局一致的数据。弱一致读可能读到过期数据,但响应更快。我们的系统支持弱一致读用于部分业务场景,减少延迟。
持久化层集成 PebbleDB,支持高吞吐写入与压缩优化。引入 Redis 热点缓存,降低高频访问数据的尾延迟。
1. 为什么选择 Pebble 而不是 RocksDB?它们的差异是什么?
回答
Pebble 是纯 Go 实现,易于集成和调试,跨平台性好,社区活跃。RocksDB 是 C++ 实现,性能稍优但集成复杂。Pebble 适合 Golang 项目,减少跨语言调用复杂度。
2. Pebble 是基于 LSM-Tree 的,它在写入性能上的优势体现在哪?
回答
Pebble 通过顺序写入日志和内存表,减少磁盘随机写入,支持后台合并(Compaction),降低写放大,保证高吞吐写入性能。
3. WAL的落盘怎么做,遇到断电问题怎么解决,这个日志具体是写在哪里的?
回答
WAL 顺序写入本地磁盘,写操作完成后才返回成功。磁盘断电时,系统重启通过 WAL 日志重放保证数据一致。日志文件存储在配置目录下的持久化存储路径。
4. 压缩策略你是如何配置的?是否手动调优过?
回答
配置了分层压缩策略,针对不同层级设置压缩频率和阈值。通过性能测试调整 Compaction 触发条件,平衡写入性能和存储空间使用。
5. Redis 缓存是如何集成的?缓存一致性怎么保证?
回答
热点数据预先加载到 Redis,读请求优先查询缓存。写操作通过异步同步机制更新缓存或使用缓存失效策略。结合版本号和过期时间保证缓存一致性。
6. 测试的时候,数据量大概有多少?
回答
测试数据量达到数百万条,存储大小约几十 GB,模拟真实业务场景数据分布和访问频率。
7. 如何识别热点数据?是否使用了 TTL、LRU、LFU 等策略?
回答
通过访问频率统计识别热点,结合 TTL 和 LFU 策略管理缓存,定期清理冷数据,保障缓存空间合理利用。
8. 你有测过 Redis 缓存命中率吗?提升了多少尾延迟?
回答
缓存命中率达到 85% 以上,尾延迟降低约 60%,有效缓解了后端存储压力。
定期快照压缩(默认每10000条),减少日志回放开销与存储占用。
1. Raft 快照的触发机制是?你怎么选“10000 条”这个阈值的?
回答
快照触发基于日志条数阈值和存储大小双重条件。10000条是经过压测后平衡回放开销与快照开销的结果,避免频繁快照导致性能下降。
2. 快照如何生成与持久化?是同步写还是异步?
回答
快照由 Leader 生成,采用异步方式写入磁盘,期间不阻塞正常读写请求,保证系统可用性。
3. 如果在快照过程中宕机怎么办?是否支持快照恢复中断续传?
回答
支持断点续传机制,重启后从上次写入进度继续,避免重复写入,提高恢复效率。
4. 快照文件与日志的管理机制?如何避免双写冲突?
回答
快照和日志分开存储,快照生成后删除对应的旧日志。通过原子替换和版本号管理避免双写冲突。
5. 日志回放慢的问题具体是怎么暴露的?优化效果如何?
回答
日志回放慢表现为节点重启恢复时间长,影响服务可用性。引入快照后,恢复时间缩短 70% 以上,系统整体可用性提升显著。
原生支持 Kubernetes,通过 StatefulSet + Headless Service 实现节点动态注册与服务发现。
1. 动态注册和服务发现怎么做的?
回答
使用 Kubernetes StatefulSet 生成有序 Pod 名称,Headless Service 取消负载均衡,Pod 通过 DNS 解析获得所有节点 IP,实现自动发现。
2. 为什么使用 StatefulSet 而不是 Deployment?
回答
StatefulSet 保证 Pod 有唯一且稳定的网络标识和存储,适合需要持久化和有序启动的状态ful应用,Deployment 无法保证。
3. Headless Service 在这里的作用是什么?与普通 Service 有什么区别?
回答
Headless Service 不分配 ClusterIP,直接返回所有 Pod IP 列表,支持客户端直连所有节点。普通 Service 有 ClusterIP,走负载均衡。
4. Raft 节点之间如何自动发现对方?Pod 重启或 IP 变化如何处理?
回答
节点通过 Headless Service 解析 DNS 获取集群所有成员 IP,Pod 重启时 DNS 会自动更新,节点重新建立连接。
5. 在 K8s 中如何实现挂掉的 Leader 自动重新加入集群?
回答
Leader 挂掉后由 Raft 选举新 Leader,旧 Leader 恢复后通过加入流程重新同步数据加入集群。
6. 是否使用 PVC 实现状态持久化?怎么保证数据不丢失?
回答
使用 PVC 绑定持久化存储,保证数据在 Pod 重启后依然保留。数据写入通过 WAL 和快照保证一致性,防止丢失。
7. 你有做过滚动升级吗?升级期间如何保障服务可用性?
回答
通过 StatefulSet 支持滚动升级,逐个替换 Pod,配合健康检查,确保集群持续可用,避免中断。
支持分区路由 与 Region 分裂(阈值64MB),实现水平扩展与负载均衡。
1. 你是如何做分区设计的?基于 Key Hash 还是 Range?
回答
采用 Range 分区设计,数据按 Key 范围划分,便于范围查询和 Region 管理。
2. Region 分裂的逻辑是什么?阈值 64MB 是如何定的?
回答
当 Region 数据超过 64MB 时触发分裂,阈值基于存储性能和内存限制调优得出,平衡性能和管理复杂度。
3. 分裂后如何更新路由信息?客户端如何感知变更?
回答
分裂后由 Leader 通知 Placement Driver 更新路由表,客户端通过配置中心或服务发现机制同步路由变更。
4. Region 重叠或热点 Region 怎么处理?有没有做 Rebalance?
回答
通过监控访问量和负载,热点 Region 会触发分裂和迁移,自动 Rebalance 以平衡负载。
5. 分裂操作是否阻塞写入?如何避免写时抖动?
回答
分裂采用异步后台执行,不阻塞前端写请求,使用多版本并发控制避免写时抖动。
6. 支持 Region 合并吗?什么时候会触发?
回答
支持 Region 合并,当某些 Region 数据量减少且连续时触发,降低分区碎片和管理开销。
通用问题
1. 你这个项目更偏向 TiKV 还是 Etcd 的设计?主要参考了哪些系统?
回答
设计更偏向 TiKV,支持分区与 Region 管理,参考了 TiKV、Etcd、CockroachDB 等分布式存储系统。
2. 整体 QPS 或写入吞吐你测试过吗?是如何压测的?
回答
使用自研压测工具和 Apache Benchmark 测试,单节点 QPS 可达数千,集群写入吞吐可线性扩展。
3. 故障模拟做过哪些?节点宕机、网络延迟、磁盘满?
回答
模拟节点宕机、网络分区、磁盘满、慢磁盘等多种故障,测试系统容错能力与恢复机制。
4. 如果现在扩展到 100+ 节点,有哪些设计需要调整?
回答
需加强路由管理、监控和调度,优化心跳和选举参数,改进分区和副本机制,保障扩展性能。
5. 这个系统目前支持哪些客户端操作?Put/Get/Delete?事务?TTL?
回答
支持基本的 Put/Get/Delete 操作,提供事务支持和 TTL 过期功能,满足分布式 KV 基础需求。
6. 和 Etcd、Redis Cluster、TiKV 等系统相比你的设计优劣点在哪里?
回答
优势在于结合了 TiKV 的分区设计和 Etcd 的强一致保证,适合高并发、强一致场景。劣势是实现复杂,部分性能尚待优化。







